Demanda, cuota de mercado y crecimiento del software de datos sintéticos para 2034
Datos históricos : 2021-2024 | Año base : 2025 | Período de pronóstico : 2026-2034Tamaño y pronóstico del mercado de software de datos sintéticos (2021-2034), participación global y regional, tendencias y análisis de oportunidades de crecimiento. Cobertura del informe: por tipo de implementación (local, en la nube); usuarios finales (gobierno, comercio minorista y electrónico, atención médica y ciencias de la vida, servicios financieros y seguros, transporte y logística, telecomunicaciones y TI, manufactura y otros) y geografía.
- Estado : Datos publicados
- Código de informe : TIPRE00012790
- Categoría : Tecnología, medios y telecomunicaciones
- Número de páginas : 150
- Formatos de informe disponibles :




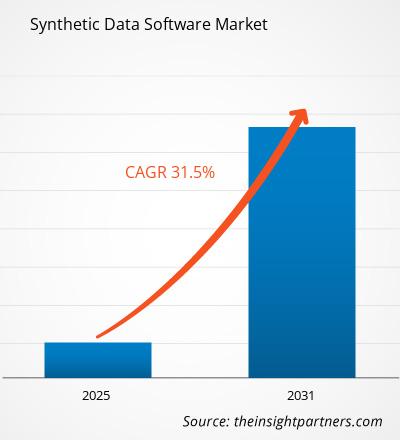
Se prevé que el mercado global de software de datos sintéticos alcance los 3.540 millones de dólares estadounidenses en 2034, frente a los 3.050 millones de dólares estadounidenses en 2025. Se espera que el mercado registre una tasa de crecimiento anual compuesta (CAGR) del 1,88% durante el período de pronóstico 2026-2034.
Análisis del mercado de software de datos sintéticos
- Se prevé que el mercado experimente un crecimiento sustancial en los próximos años. Este crecimiento se debe a factores como la creciente preocupación por la privacidad, las amenazas a la ciberseguridad, la necesidad de datos personalizados y flexibles, y el acceso a datos en tiempo real.
- Las principales tendencias del mercado incluyen las innovaciones tecnológicas y la digitalización. Siguiendo estas tendencias y aprovechando las oportunidades, el mercado del software de datos sintéticos puede crecer de forma constante con el tiempo.
Descripción general del mercado de software de datos sintéticos
- Los datos sintéticos son un tipo de datos generados artificialmente que poseen propiedades similares a las de los datos generados manualmente de forma tradicional. El software para generar datos sintéticos es una herramienta digital que se utiliza para ello.
- La privacidad de los datos, el acceso a datos en tiempo real, la reducción de costes, un flujo de trabajo más eficiente y optimizado, y un desarrollo más rápido son algunas de las ventajas del software de datos sintéticos. Los avances tecnológicos, como el aprendizaje automático y la inteligencia artificial, ofrecen una oportunidad prometedora para el mercado de este tipo de software.
Aspectos destacados de la investigación de mercado
- El mercado global de software de datos sintéticos alcanzó un valor de 3.050 millones de dólares estadounidenses en 2025.
- Se prevé que el tamaño del mercado anual alcance los 3.540 millones de dólares estadounidenses para el año 2034.
- Se prevé que el mercado total disponible (TAM) durante el período 2026-2034 alcance aproximadamente los 30.160 millones de dólares estadounidenses.
- Se prevé que el mercado registre una tasa de crecimiento anual compuesta (CAGR) del 1,88% durante el período de pronóstico.
- Estados Unidos representa un mercado clave, respaldado por la superación de las preocupaciones sobre la privacidad y la seguridad de los datos, así como por la evolución de la dinámica del sector.
- El análisis de mercado abarca América del Norte, Europa, Asia-Pacífico, América del Sur y Central, Oriente Medio y África, con un crecimiento evaluado durante el período de pronóstico.
- Se espera que las oportunidades de mercado, como la integración con tecnologías avanzadas como la inteligencia artificial, influyan en la dinámica del mercado y en el mercado potencial.
- El informe presenta perfiles de participantes de la industria, incluyendo Mostly AI, Inc., Nvidia Corp., Meta, CVEDIA Inc., Amazon.com, Inc., Synthesis AI, IBM Corp., Microsoft Corp., Datagen, Inc., Gretel Labs, al tiempo que analiza estrategias competitivas y desarrollos innovadores.
Personaliza este informe para adaptarlo a tus necesidades.
Obtén PERSONALIZACIÓN GRATUITAMercado de software de datos sintéticos: Perspectivas estratégicas
-
Descubra las principales tendencias del mercado que se recogen en este informe.Esta muestra GRATUITA incluirá análisis de datos, que abarcan desde tendencias de mercado hasta estimaciones y pronósticos.
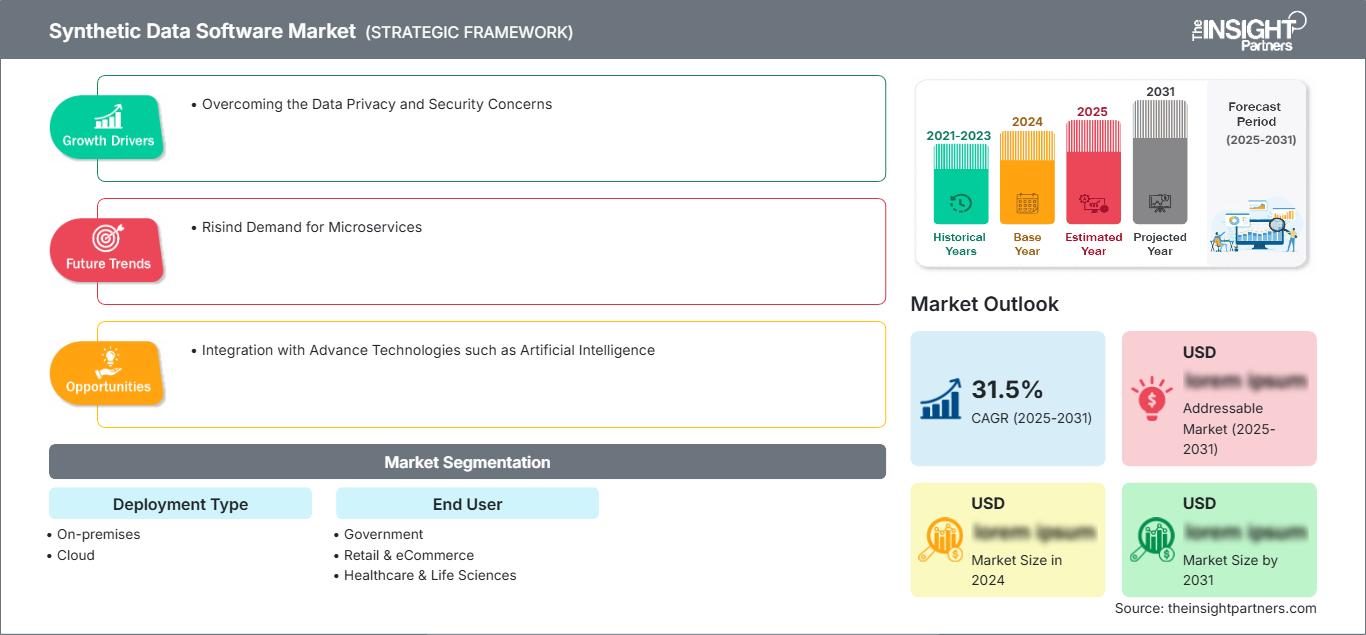
Factores impulsores y oportunidades del mercado de software de datos sintéticos
Superar las preocupaciones sobre la privacidad y la seguridad de los datos
- El acceso a datos del mundo real se ve dificultado por las estrictas regulaciones impuestas por diversas organizaciones y leyes, como la Ley de Privacidad del Consumidor de California (CCPA), el Reglamento General de Protección de Datos (RGPD), entre otras. La creciente demanda de privacidad de datos ha llevado a organizaciones y empresas a gestionar sus datos con la máxima cautela.
- El software de datos sintéticos permite a las organizaciones generar datos auténticos del mundo real, preservando al mismo tiempo la privacidad de la empresa y cumpliendo con las normas y regulaciones impuestas.
Integración con tecnologías avanzadas como la inteligencia artificial.
- Tecnologías como la IA ayudarán a generar datos más auténticos, precisos y reales. La IA tiende a optimizar los flujos de trabajo automatizando diversas tareas manuales y generando datos eficientes. También ayuda a adaptar los datos a las necesidades de sectores específicos. La IA representa una oportunidad muy prometedora para el mercado del software de datos sintéticos.
Análisis de segmentación del informe de mercado de software de datos sintéticos
Los segmentos clave que contribuyeron a la elaboración del análisis de mercado del software de datos sintéticos son el tipo de implementación y los usuarios finales.
- Según el tipo de implementación, el mercado se divide en local y en la nube. El segmento local representó una cuota de mercado significativa en 2023.
- Según los usuarios finales, el mercado se segmenta en gobierno, comercio minorista y electrónico, salud y ciencias de la vida, servicios financieros y seguros (BFSI), transporte y logística, telecomunicaciones e informática, manufactura y otros. El segmento gubernamental representó una cuota de mercado significativa en 2023.
Análisis de la cuota de mercado del software de datos sintéticos por geografía
El alcance geográfico del informe de mercado del software de datos sintéticos se divide principalmente en cinco regiones: América del Norte, Asia Pacífico, Europa, Oriente Medio y África, y América del Sur y Central.
Se prevé que el auge en el uso de la generación de datos sintéticos en los sectores de banca, finanzas y seguros (BFSI), comercio minorista, salud y otros, con el objetivo de optimizar las operaciones comerciales y la satisfacción del cliente, genere perspectivas de crecimiento rentables para el mercado de generación de datos sintéticos en Norteamérica. Se pronostica que la región de Asia-Pacífico experimentará la expansión más significativa en los próximos años. Este crecimiento está vinculado a la creciente integración de tecnologías avanzadas como la IA/ML y al aumento en la adopción de servicios en la nube, lo que impulsa el crecimiento del mercado de generación de datos sintéticos en esta área geográfica.
Alcance del informe de mercado de software de datos sintéticos
| Atributo del informe | Detalles |
|---|---|
| Tamaño del mercado en 2025 | 3.050 millones de dólares estadounidenses |
| Tamaño del mercado para 2034 | 3.540 millones de dólares estadounidenses |
| Tasa de crecimiento anual compuesta global (2026 - 2034) | 1,88% |
| Datos históricos | 2021-2024 |
| Período de pronóstico | 2026-2034 |
| Segmentos cubiertos |
Por tipo de despliegue
|
| Regiones y países incluidos |
América del norte
|
| Líderes del mercado y perfiles de empresas clave |
|
Densidad de los actores del mercado de software de datos sintéticos: comprender su impacto en la dinámica empresarial.
El mercado de software de datos sintéticos está experimentando un rápido crecimiento, impulsado por la creciente demanda de los usuarios finales debido a factores como la evolución de las preferencias de los consumidores, los avances tecnológicos y una mayor concienciación sobre los beneficios del producto. A medida que aumenta la demanda, las empresas amplían su oferta, innovan para satisfacer las necesidades de los consumidores y aprovechan las tendencias emergentes, lo que impulsa aún más el crecimiento del mercado.
Noticias y novedades recientes del mercado de software de datos sintéticos
El mercado de software de datos sintéticos se evalúa mediante la recopilación de datos cualitativos y cuantitativos tras una investigación primaria y secundaria, que incluye publicaciones corporativas importantes, datos de asociaciones y bases de datos. A continuación, se enumeran algunos de los avances en el mercado de software de datos sintéticos:
- Anonos, proveedor de la única tecnología que protege los datos en uso con una precisión del 100 %, anunció hoy la adquisición de Statice GmbH, con sede en Berlín, proveedor de software de datos sintéticos. Con la incorporación de la solución Statice, que genera nuevos puntos de datos que preservan la privacidad y reflejan las propiedades estadísticas de los datos originales, Anonos amplía su capacidad para proporcionar una plataforma integral que acelera la obtención de información valiosa para diversos casos de uso, al tiempo que mejora la protección y el aprovechamiento de los datos. La tecnología de datos sintéticos de Statice se integrará en la plataforma Anonos Data Embassy y estará disponible a finales de este trimestre. Esta adquisición se produce tras el reciente anuncio de Anonos de una nueva ronda de financiación para el crecimiento por valor de 50 millones de dólares, respaldada por su cartera de propiedad intelectual, facilitada por Aon (NYSE: AON) y liderada por GT Investment Partners («Ghost Tree Partners»).
(Fuente: Anonos, comunicado de prensa, noviembre de 2022)
Cobertura y entregables del informe de mercado de software de datos sintéticos
El informe “Tamaño y pronóstico del mercado de software de datos sintéticos (2021–2034)” proporciona un análisis detallado del mercado que abarca las siguientes áreas:
- Tamaño y pronóstico del mercado de software de datos sintéticos a nivel global, regional y nacional para todos los segmentos clave del mercado cubiertos en el alcance.
- Tendencias del mercado de software de datos sintéticos, así como dinámicas del mercado como factores impulsores, limitaciones y oportunidades clave.
- Análisis detallado PEST/Cinco Fuerzas de Porter y análisis FODA.
- Análisis del mercado de software de datos sintéticos que abarca las principales tendencias del mercado, el marco global y regional, los principales actores, las regulaciones y los desarrollos recientes del mercado.
- Análisis del panorama de la industria y de la competencia, que abarca la concentración del mercado, el análisis de mapas de calor, los principales actores y los desarrollos recientes para el mercado de software de datos sintéticos.
- Perfiles detallados de las empresas

Ankita es una profesional dinámica en investigación de mercados y consultoría con más de 8 años de experiencia en los sectores de tecnología, medios de comunicación, TIC, electrónica y semiconductores. Ha liderado y ejecutado con éxito más de 100 proyectos de consultoría e investigación para clientes globales como Microsoft, Oracle, NEC Corporation, SAP, KPMG y Expeditors International. Sus principales competencias incluyen la evaluación de mercado, el análisis de datos, la previsión, la formulación de estrategias, la inteligencia competitiva y la redacción de informes.
Ankita es experta en la gestión de ciclos completos de proyecto, desde el diseño de propuestas de preventa y las conversaciones con los clientes hasta la entrega de información práctica posventa. Es experta en la gestión de equipos multifuncionales, la estructuración de módulos de investigación complejos y la alineación de soluciones con los objetivos de negocio específicos del cliente. Sus excelentes habilidades de comunicación, liderazgo y presentación le han permitido obtener constantemente resultados orientados al valor en entornos de mercado dinámicos y en constante evolución.
- Análisis histórico (2 años), año base, pronóstico (7 años) con CAGR
- Análisis PEST y FODA
- Tamaño del mercado, valor/volumen: global, regional y nacional
- Industria y panorama competitivo
- Conjunto de datos de Excel
Testimonios
El informe de mercado de sistemas SCADA de Insight Partners es completo y ofrece información valiosa sobre las tendencias actuales y las previsiones futuras. El equipo fue altamente profesional, receptivo y me brindó un gran apoyo en todo momento. Estamos muy satisfechos y recomendamos ampliamente sus servicios.
RAN KEDEM Socio, Reali Technologies LTDsSolicité un informe sobre un mercado de software muy específico y el equipo lo elaboró en pocos días. La información era muy relevante y estaba bien presentada. Posteriormente, solicité algunos cambios y adiciones al informe. El equipo fue muy receptivo y recibí el informe final en menos de una semana.
JEAN-HERVE JENN Presidente, Future AnalyticaTrabajamos con The Insight Partners para un importante estudio y pronóstico de mercado. Nos brindaron una visión clara de las oportunidades y los riesgos, lo que nos ayudó a definir nuestros planes. Su investigación fue fácil de usar y se basó en datos sólidos. Nos ayudó a tomar decisiones inteligentes y seguras. Los recomendamos ampliamente.
PIYUSH NAGPAL Vicepresidente Sénior, , High Beam GlobalThe Insight Partners realizó una investigación de mercado profunda y bien estructurada con una sólida experiencia en el sector. Su equipo fue profesional y receptivo en todo momento. El sitio web, fácil de usar, facilitó el acceso a los informes del sector. Los recomendamos ampliamente por sus servicios de investigación confiables y de alta calidad.
YUKIHIKO ADACHI Director Ejecutivo, , Deep Blue, LLCEsta es la primera vez que compro un informe de mercado de The Insight Partners. Aunque al principio tenía dudas, visité su sitio web y me sentí más cómodo al arriesgarme y comprarlo. Estoy completamente satisfecho con la calidad del informe y el servicio al cliente. Tenía varias preguntas y comentarios sobre el informe inicial, pero después de un par de conversaciones por correo electrónico con su analista, creo que tengo un informe que puedo usar como base para nuestro proceso de planificación estratégica. Muchas gracias por tomarse el tiempo y hacer de esta una experiencia positiva. Sin duda, recomendaré sus servicios y serán mi primera opción cuando necesitemos más datos de mercado.
JOHN SUZUKI Presidente y Director Ejecutivo, Director de la Junta Directiva, BK TechnologiesAgradezco su apoyo y la profesionalidad que demostraron al atender mi solicitud de información sobre el mercado de diagnóstico in vitro (IVD) para enfermedades infecciosas en Nigeria. Agradezco su paciencia, su orientación y su disposición a ofrecerme un descuento, lo que finalmente nos permitió cerrar un trato. Espero poder colaborar con The Insight Partners en el futuro, gracias a la impresión que me causó este primer encuentro.
DRA. CHIJIOKE ONYIA, DIRECTORA GENERAL, PineCrest Healthcare Ltd.Razón para comprar
- Toma de decisiones informada
- Comprensión de la dinámica del mercado
- Análisis competitivo
- Información sobre clientes
- Pronósticos del mercado
- Mitigación de riesgos
- Planificación estratégica
- Justificación de la inversión
- Identificación de mercados emergentes
- Mejora de las estrategias de marketing
- Impulso de la eficiencia operativa
- Alineación con las tendencias regulatorias










Desbloquea descuentos exclusivos en informes
Consultar ahora



 Obtenga una muestra gratuita para - Mercado de software de datos sintéticos
Obtenga una muestra gratuita para - Mercado de software de datos sintéticos