Nachfrage, Marktanteil und Wachstum des Marktes für Software zur synthetischen Datenentwicklung bis 2034
Historische Daten : 2021-2024 | Basisjahr : 2025 | Prognosezeitraum : 2026-2034Marktgröße und Prognose für Software zur Generierung synthetischer Daten (2021–2034): Globaler und regionaler Marktanteil, Trends und Wachstumspotenzialanalyse. Berichtsabdeckung: Nach Bereitstellungsart (On-Premises, Cloud); Endnutzern (Regierung, Einzelhandel & E-Commerce, Gesundheitswesen & Biowissenschaften, Banken, Finanzdienstleistungen & Versicherungen, Transport & Logistik, Telekommunikation & IT, Fertigung und Sonstige) und Geografie
- Status : Veröffentlichte Daten
- Berichtscode : TIPRE00012790
- Kategorie : Technologie, Medien und Telekommunikation
- Anzahl der Seiten : 150
- Verfügbare Berichtsformate :




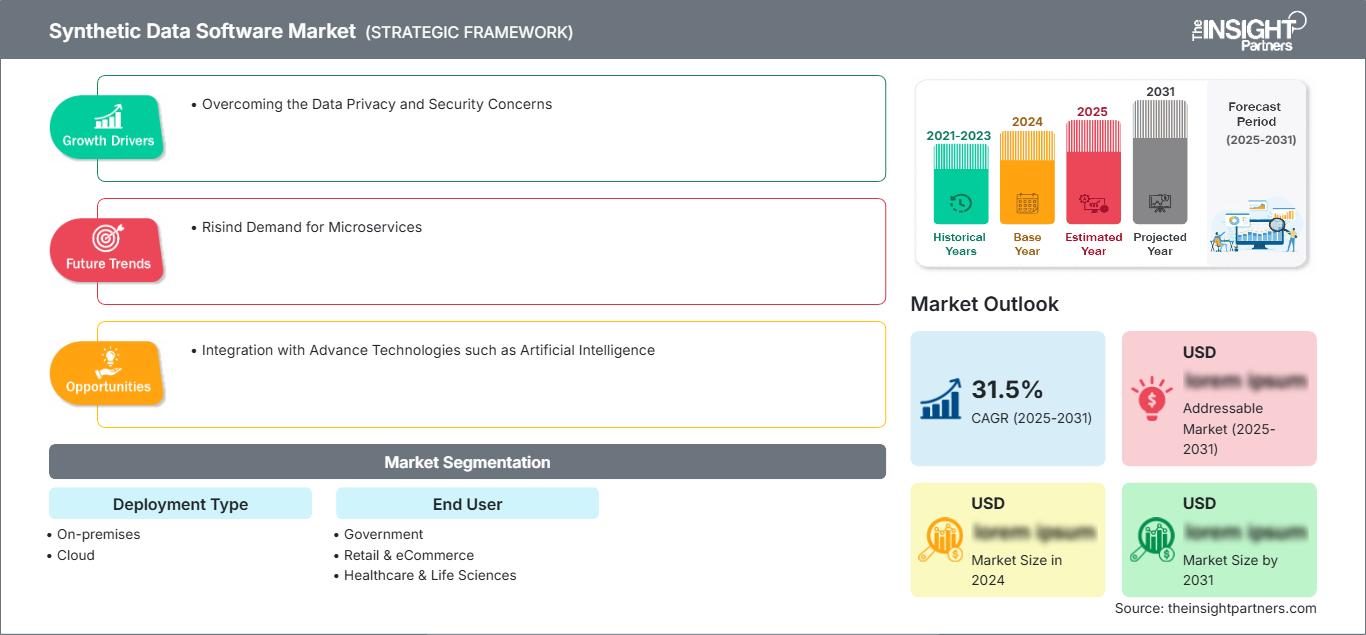
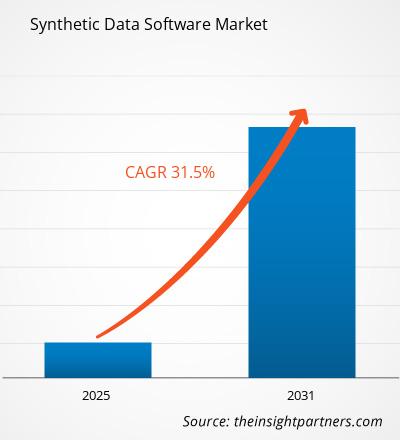
Der globale Markt für Software zur Erzeugung synthetischer Daten wird bis 2034 voraussichtlich ein Volumen von 3,54 Milliarden US-Dollar erreichen, gegenüber 3,05 Milliarden US-Dollar im Jahr 2025. Es wird erwartet, dass der Markt im Prognosezeitraum 2026-2034 eine durchschnittliche jährliche Wachstumsrate (CAGR) von 1,88 % verzeichnen wird.
Marktanalyse für Software zur synthetischen Daten
- Der Markt dürfte in den kommenden Jahren ein deutliches Wachstum verzeichnen. Gründe hierfür sind unter anderem zunehmende Bedenken hinsichtlich des Datenschutzes, Bedrohungen der Cybersicherheit, personalisierte und flexible Daten sowie der Zugriff auf Echtzeitdaten.
- Zu den wichtigsten Markttrends zählen technologische Innovationen und die Digitalisierung. Durch die Berücksichtigung dieser Trends und die Nutzung der sich bietenden Chancen kann der Markt für Software zur synthetischen Datenentwicklung im Laufe der Zeit stetig wachsen.
Marktübersicht für Software zur synthetischen Daten
- Synthetische Daten sind künstlich erzeugte Daten, die jedoch Eigenschaften herkömmlicher, manuell erstellter Daten aufweisen. Software zur Erzeugung synthetischer Daten ist ein digitales Werkzeug, das zur Generierung solcher Daten verwendet wird.
- Datenschutz, Zugriff auf Echtzeitdaten, geringere Kosten, effizientere und verbesserte Arbeitsabläufe sowie schnellere Entwicklung sind einige der Vorteile von Software zur Generierung synthetischer Daten. Technologische Fortschritte wie maschinelles Lernen und künstliche Intelligenz bieten vielversprechende Möglichkeiten für den Markt dieser Software.
Highlights der Marktforschung
- Der globale Markt für Software zur Erzeugung synthetischer Daten wurde im Jahr 2025 auf 3,05 Milliarden US-Dollar geschätzt.
- Es wird erwartet, dass das jährliche Marktvolumen bis 2034 3,54 Milliarden US-Dollar erreichen wird.
- Der gesamte adressierbare Markt (TAM) wird im Zeitraum 2026-2034 voraussichtlich rund 30,16 Milliarden US-Dollar erreichen.
- Es wird erwartet, dass der Markt im Prognosezeitraum eine durchschnittliche jährliche Wachstumsrate (CAGR) von 1,88 % verzeichnen wird.
- Die Vereinigten Staaten stellen einen Schlüsselmarkt dar, was durch die Überwindung der Bedenken hinsichtlich Datenschutz und Datensicherheit sowie die sich entwickelnde Branchendynamik unterstützt wird.
- Die Marktanalyse umfasst Nordamerika, Europa, den asiatisch-pazifischen Raum, Süd- und Mittelamerika, den Nahen Osten und Afrika, wobei das Wachstum über den gesamten Prognosezeitraum bewertet wird.
- Marktchancen wie die Integration fortschrittlicher Technologien, beispielsweise künstlicher Intelligenz, werden voraussichtlich die Marktdynamik und den adressierbaren Markt beeinflussen.
- Der Bericht stellt Branchenteilnehmer wie Mostly AI, Inc., Nvidia Corp., Meta, CVEDIA Inc., Amazon.com, Inc., Synthesis AI, IBM Corp., Microsoft Corp., Datagen, Inc. und Gretel Labs vor und analysiert Wettbewerbsstrategien und Innovationsentwicklungen.
Passen Sie diesen Bericht Ihren Anforderungen an.
Kostenlose AnpassungMarkt für Software zur Datensynthese: Strategische Einblicke
-
Ermitteln Sie die wichtigsten Markttrends dieses Berichts.Diese KOSTENLOSE Probe beinhaltet eine Datenanalyse, die von Markttrends bis hin zu Schätzungen und Prognosen reicht.
Markttreiber und Chancen für Software zur synthetischen Daten
Überwindung der Bedenken hinsichtlich Datenschutz und Datensicherheit
- Der Zugriff auf reale Daten gestaltet sich aufgrund strenger Vorschriften verschiedener Organisationen und Gesetze wie dem California Consumer Privacy Act (CCPA), der Datenschutz-Grundverordnung (DSGVO) und anderen schwierig. Die steigende Nachfrage nach Datenschutz hat Organisationen und Unternehmen veranlasst, ihre Daten mit größter Sorgfalt zu behandeln.
- Software zur Erzeugung synthetischer Daten ermöglicht es Organisationen, authentische, realweltliche Daten zu generieren und gleichzeitig die Vertraulichkeit des Unternehmens zu wahren sowie die geltenden Regeln und Vorschriften einzuhalten.
Integration mit fortschrittlichen Technologien wie künstlicher Intelligenz
- Technologien wie KI tragen dazu bei, authentischere, genauere und realitätsnähere Daten zu generieren. KI optimiert Arbeitsabläufe durch die Automatisierung manueller Aufgaben und die effiziente Datengenerierung. Zudem ermöglicht sie die Anpassung von Daten an die Bedürfnisse spezifischer Branchen. KI eröffnet vielversprechende Chancen für den Markt synthetischer Datensoftware.
Marktbericht: Segmentierungsanalyse für Software zur synthetischen Daten
Die wichtigsten Segmente, die zur Ableitung der Marktanalyse für Software zur Erzeugung synthetischer Daten beigetragen haben, sind die Art der Bereitstellung und die Endnutzer.
- Basierend auf dem Bereitstellungstyp ist der Markt in On-Premises und Cloud unterteilt. Das On-Premises-Segment hielt 2023 einen signifikanten Marktanteil.
- Basierend auf den Endnutzern ist der Markt in folgende Segmente unterteilt: Regierung, Einzelhandel & E-Commerce, Gesundheitswesen & Biowissenschaften, Banken, Finanzdienstleistungen & Versicherungen (BFSI), Transport & Logistik, Telekommunikation & IT, Fertigung und Sonstige. Das Segment Regierung hielt 2023 einen signifikanten Marktanteil.
Marktanteilsanalyse für Software zur synthetischen Daten nach Regionen
Der geografische Umfang des Marktberichts für Software zur synthetischen Datenverteilung ist hauptsächlich in fünf Regionen unterteilt: Nordamerika, Asien-Pazifik, Europa, Naher Osten & Afrika sowie Süd- & Mittelamerika.
Der zunehmende Einsatz synthetischer Daten in den Bereichen Banken, Finanzdienstleistungen und Versicherungen (BFSI), Einzelhandel, Gesundheitswesen und anderen Branchen, der auf die Optimierung von Geschäftsabläufen und die Steigerung der Kundenzufriedenheit abzielt, dürfte dem Markt für synthetische Daten in Nordamerika profitable Wachstumschancen eröffnen. Die Region Asien-Pazifik wird in den kommenden Jahren voraussichtlich das stärkste Wachstum verzeichnen. Dieses Wachstum ist auf die zunehmende Integration fortschrittlicher Technologien wie KI/ML und die verstärkte Nutzung cloudbasierter Dienste zurückzuführen, die das Wachstum des Marktes für synthetische Daten in dieser Region antreiben.
Berichtsumfang zum Markt für Software zur synthetischen Daten
| Berichtattribute | Details |
|---|---|
| Marktgröße im Jahr 2025 | 3,05 Milliarden US-Dollar |
| Marktgröße bis 2034 | 3,54 Milliarden US-Dollar |
| Globale durchschnittliche jährliche Wachstumsrate (2026 - 2034) | 1,88 % |
| Historische Daten | 2021-2024 |
| Prognosezeitraum | 2026–2034 |
| Abgedeckte Segmente |
Nach Bereitstellungstyp
|
| Abgedeckte Regionen und Länder |
Nordamerika
|
| Marktführer und wichtige Unternehmensprofile |
|
Marktdichte synthetischer Datensoftware: Auswirkungen auf die Geschäftsdynamik verstehen
Der Markt für Software zur Generierung synthetischer Daten wächst rasant, angetrieben durch die steigende Nachfrage der Endnutzer. Gründe hierfür sind unter anderem sich wandelnde Verbraucherpräferenzen, technologische Fortschritte und ein wachsendes Bewusstsein für die Vorteile des Produkts. Mit steigender Nachfrage erweitern Unternehmen ihr Angebot, entwickeln innovative Lösungen, um den Kundenbedürfnissen gerecht zu werden, und nutzen neue Trends, was das Marktwachstum zusätzlich beflügelt.
Neuigkeiten und aktuelle Entwicklungen auf dem Markt für Software zur synthetischen Daten
Der Markt für Software zur Generierung synthetischer Daten wird anhand qualitativer und quantitativer Daten aus Primär- und Sekundärforschung analysiert. Diese umfasst wichtige Unternehmensveröffentlichungen, Verbandsdaten und Datenbanken. Einige Entwicklungen auf dem Markt für Software zur Generierung synthetischer Daten sind nachfolgend aufgeführt:
- Anonos, Anbieter der einzigen Technologie, die Daten während der Nutzung mit 100%iger Genauigkeit schützt, gab heute die Übernahme der Berliner Statice GmbH, einem Anbieter von Software für synthetische Daten, bekannt. Mit der Integration der Statice-Lösung, die neue, datenschutzkonforme Datenpunkte generiert, welche die statistischen Eigenschaften der Originaldaten widerspiegeln, erweitert Anonos seine umfassende Plattform. Diese ermöglicht schnelle Dateneinblicke für verschiedene Anwendungsfälle und verbessert gleichzeitig den Schutz und die Nutzung von Daten. Die Statice-Technologie für synthetische Daten wird in die Anonos Data Embassy-Plattform integriert und ist ab diesem Quartal verfügbar. Die Übernahme folgt auf die kürzlich erfolgte Ankündigung von Anonos über eine neue Wachstumsfinanzierung in Höhe von 50 Millionen US-Dollar, die durch das Portfolio an geistigem Eigentum besichert ist. Die Finanzierung wurde von Aon (NYSE: AON) ermöglicht und von GT Investment Partners („Ghost Tree Partners“) angeführt.
(Quelle: Anonymus, Pressemitteilung, November 2022)
Marktbericht zu Software für synthetische Daten: Abdeckung und Ergebnisse
Der Bericht „Marktgröße und Prognose für Software zur Erzeugung synthetischer Daten (2021–2034)“ bietet eine detaillierte Analyse des Marktes, die folgende Bereiche abdeckt:
- Marktgröße und Prognose für Software zur synthetischen Datenerzeugung auf globaler, regionaler und Länderebene für alle wichtigen Marktsegmente, die im Rahmen des Berichts abgedeckt werden
- Trends im Markt für Software zur Erzeugung synthetischer Daten sowie Marktdynamiken wie Treiber, Hemmnisse und wichtige Chancen
- Detaillierte PEST-/Porter-Fünf-Kräfte- und SWOT-Analyse
- Marktanalyse für Software zur synthetischen Daten: Wichtige Markttrends, globale und regionale Rahmenbedingungen, Hauptakteure, regulatorische Rahmenbedingungen und aktuelle Marktentwicklungen
- Branchenlandschafts- und Wettbewerbsanalyse mit Marktkonzentration, Heatmap-Analyse, führenden Akteuren und aktuellen Entwicklungen im Markt für Software zur synthetischen Daten
- Detaillierte Unternehmensprofile

Ankita ist eine dynamische Marktforschungs- und Beratungsexpertin mit über 8 Jahren Erfahrung in den Bereichen Technologie, Medien, IKT sowie Elektronik und Halbleiter. Sie hat über 100 Beratungs- und Forschungsaufträge für globale Kunden wie Microsoft, Oracle, NEC Corporation, SAP, KPMG und Expeditors International erfolgreich geleitet und durchgeführt. Zu ihren Kernkompetenzen gehören Marktbewertung, Datenanalyse, Prognose, Strategieformulierung, Wettbewerbsbeobachtung und das Verfassen von Berichten. Ankita ist versiert in der Abwicklung kompletter Projektzyklen – von der Angebotserstellung vor dem Verkauf und Kundengesprächen bis hin zur Bereitstellung umsetzbarer Erkenntnisse nach dem Verkauf. Sie ist versiert in der Leitung funktionsübergreifender Teams, der Strukturierung komplexer Forschungsmodule und der Ausrichtung von Lösungen an kundenspezifischen Geschäftszielen. Ihre ausgezeichneten Kommunikationsfähigkeiten, Führungsqualitäten und Präsentationsfähigkeiten haben es ihr ermöglicht, in einem schnelllebigen und sich entwickelnden Marktumfeld stets wertorientierte Ergebnisse zu liefern.
- Historische Analyse (2 Jahre), Basisjahr, Prognose (7 Jahre) mit CAGR
- PEST- und SWOT-Analyse
- Marktgröße Wert/Volumen – Global, Regional, Land
- Branchen- und Wettbewerbslandschaft
- Excel-Datensatz
Erfahrungsberichte
Der SCADA-Systemmarktbericht von Insight Partners ist umfassend und bietet wertvolle Einblicke in aktuelle Trends und Zukunftsprognosen. Das Team war durchweg hochprofessionell, reaktionsschnell und hilfsbereit. Wir sind sehr zufrieden und können die Dienstleistungen wärmstens empfehlen.
RAN KEDEM Partner, Reali Technologies LTDsIch habe einen Bericht über einen sehr spezifischen Softwaremarkt angefordert, und das Team hat ihn innerhalb weniger Tage erstellt. Die Informationen waren sehr relevant und gut präsentiert. Anschließend habe ich einige Änderungen und Ergänzungen zum Bericht angefordert. Das Team reagierte erneut sehr schnell, und ich erhielt den Abschlussbericht in weniger als einer Woche.
JEAN-HERVE JENN Vorsitzende, Future AnalyticaWir haben mit The Insight Partners für eine wichtige Marktstudie und Prognose zusammengearbeitet. Sie gaben uns klare Einblicke in Chancen und Risiken, die uns bei der Gestaltung unserer Pläne halfen. Ihre Recherchen waren benutzerfreundlich und basierten auf soliden Daten. Sie halfen uns, kluge und sichere Entscheidungen zu treffen. Wir können sie wärmstens empfehlen.
PIYUSH NAGPAL Sr. Vizepräsident, Fernlicht GlobalDie Insight Partners lieferten aufschlussreiche, gut strukturierte Marktforschung mit fundierter Fachkompetenz. Ihr Team war durchweg professionell und reaktionsschnell. Die benutzerfreundliche Website ermöglichte den Zugriff auf Branchenberichte. Wir empfehlen sie wärmstens für zuverlässige und hochwertige Forschungsdienstleistungen.
YUKIHIKO ADACHI Geschäftsführer, Deep Blue, LLC.Dies ist das erste Mal, dass ich einen Marktbericht von The Insight Partners erworben habe. Obwohl ich zunächst unsicher war, besuchte ich die Website und fühlte mich dann sicherer, das Risiko einzugehen und einen Marktbericht zu kaufen. Ich bin mit der Qualität des Berichts und dem Kundenservice rundum zufrieden. Ich hatte einige Fragen und Anmerkungen zum ersten Bericht, aber nach einigen E-Mail-Gesprächen mit dem Analysten bin ich überzeugt, dass ich einen Bericht habe, den ich als Input für unseren strategischen Planungsprozess verwenden kann. Vielen Dank, dass Sie sich die Zeit genommen und dies zu einer positiven Erfahrung gemacht haben. Ich werde Ihren Service auf jeden Fall weiterempfehlen und Sie werden meine erste Anlaufstelle sein, wenn wir weitere Marktdaten benötigen.
JOHN SUZUKI Präsident und Chief Executive Officer, Vorstandsmitglied, BK TechnologiesIch möchte mich für Ihre Unterstützung und die Professionalität bedanken, die Sie bei der Bearbeitung meiner Informationsanfrage zum IVD-Markt für Infektionskrankheiten in Nigeria gezeigt haben. Ich schätze Ihre Geduld, Ihre Beratung und die Tatsache, dass Sie bereit waren, einen Rabatt anzubieten, der uns schließlich den Abschluss eines Geschäfts ermöglichte. Ich freue mich darauf, The Insight Partners in Zukunft wieder zu beauftragen, dank des Eindrucks, den Sie bei dieser ersten Begegnung bei mir hinterlassen haben.
DR. CHIJIOKE ONYIA GESCHÄFTSFÜHRERIN, PineCrest Healthcare Ltd.Grund zum Kauf
- Fundierte Entscheidungsfindung
- Marktdynamik verstehen
- Wettbewerbsanalyse
- Kundeneinblicke
- Marktprognosen
- Risikominimierung
- Strategische Planung
- Investitionsbegründung
- Identifizierung neuer Märkte
- Verbesserung von Marketingstrategien
- Steigerung der Betriebseffizienz
- Anpassung an regulatorische Trends










Exklusive Berichtsrabatte freischalten
Jetzt anfragen



 Kostenlose Probe anfordern für - Markt für synthetische Datensoftware
Kostenlose Probe anfordern für - Markt für synthetische Datensoftware