Croissance, taille, part, tendances, analyse des principaux acteurs et prévisions du marché de la classification des données jusqu’en 2027
Données historiques : 2017-2018 | Année de référence : 2019 | Période de prévision : 2020-2027Prévisions du marché de la classification des données jusqu'en 2027 - Impact de la COVID-19 et analyse mondiale par solution (solutions, services) ; application (GRC, protection Web, mobile et e-mail, autres) ; secteur d'activité (BFSI, informatique et télécommunications, médias et divertissement, commerce de détail, éducation, santé, autres)
- Statut : Publié
- Code du rapport : TIPRE00003043
- Catégorie : Technologie, médias et télécommunications
- Nombre de pages : 151
- Formats de rapport disponibles :




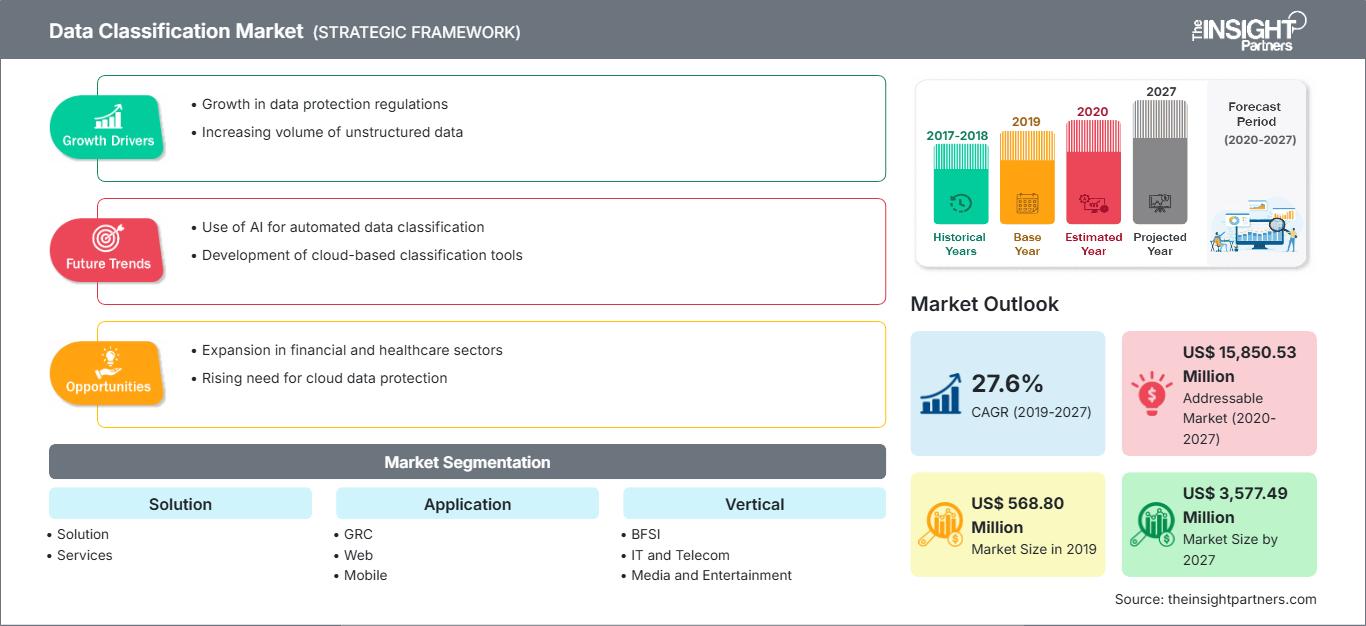
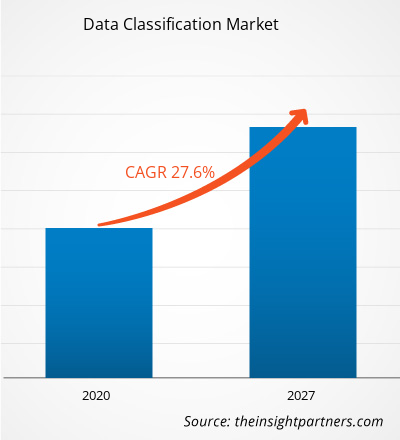
Le marché de la classification des données était évalué à 568,80 millions de dollars américains en 2019 et devrait atteindre 3 577,49 millions de dollars américains d'ici 2027. Le marché de la classification des données devrait croître à un TCAC de 27,6 % entre 2020 et 2027.
La classification des données est un outil qui permet de classer d'énormes quantités de données dans divers onglets afin d'en optimiser l'exploitation tout en préservant la confidentialité des données confidentielles. La commercialisation des lois sur la protection des données, telles que le RGPD et la loi HIPAA (Health Insurance Portability and Accountability Act), est directement liée à l'impact sur la portée de la classification des données dans le monde. La croissance des données d'entreprise et des migrations vers le cloud, l'accélération de l'identification des données personnelles, les menaces pour la confidentialité dans les e-mails, l'exploitation de l'apprentissage automatique et la convergence de la gestion et de la protection des données sont parmi les facteurs qui jouent un rôle important dans l'accélération de la portée de la classification des données. La classification des données connaît un essor important dans le monde entier. Le déploiement d'outils de classification des données pour lutter contre les cybermenaces ouvre la voie à la croissance du marché. De plus, l'importance croissante accordée aux lois sur la protection des données par les autorités gouvernementales de pays comme le Royaume-Uni, les États-Unis, l'Allemagne et Singapour stimule l'adoption de la classification des données. De plus, l'intégration de technologies sophistiquées telles que l'apprentissage automatique et l'intelligence artificielle dans les outils de classification des données accélère la production et la productivité de l'ensemble des entreprises. Par exemple, 40 % des entreprises américaines utilisent l'apprentissage automatique pour améliorer leurs stratégies commerciales et marketing, et les banques européennes ont constaté une augmentation de 10 % de leurs ventes de produits et une baisse de 20 % de leur taux de désabonnement grâce à l'apprentissage automatique. Le marché de la classification des données est segmenté en composants, applications, secteurs verticaux et géographiques. En fonction des composants, le segment des solutions détient la plus grande part du marché mondial de la classification des données. La solution de classification des données dérive des contrôles de sécurité appliqués à un ensemble de données spécifique. En termes d'applications, le segment de la protection web, mobile et e-mail a dominé le marché mondial de la classification des données en 2019. Avec l'essor de l'utilisation des e-mails, des applications mobiles et web pour le transfert de données entre entreprises et secteurs d'activité, les outils de protection et de classification des données sont devenus indispensables. Par secteur d'activité, le segment BFSI a représenté une part substantielle en 2019 et devrait maintenir sa domination sur la période de prévision. Géographiquement, le marché est segmenté en cinq grandes régions : Amérique du Nord, Europe, Asie-Pacifique (APAC), Moyen-Orient et Afrique (MEA) et Amérique du Sud (SAM).
Vous bénéficierez d’une personnalisation sur n’importe quel rapport - gratuitement - y compris des parties de ce rapport, ou une analyse au niveau du pays, un pack de données Excel, ainsi que de profiter d’offres exceptionnelles et de réductions pour les start-ups et les universités
Marché de la classification des données: Perspectives stratégiques
-
Obtenez les principales tendances clés du marché de ce rapport.Cet échantillon GRATUIT comprendra une analyse de données, allant des tendances du marché aux estimations et prévisions.
Les États-Unis, l'Allemagne, le Royaume-Uni et Singapour font partie des pays où le gouvernement a réglementé les entreprises informatiques par des lois sur le chiffrement et la protection des données. Ces entreprises technologiques y trouvent des opportunités pour promouvoir leurs services de classification des données. Les gouvernements américain et britannique ont mis en place des systèmes de classification des données à trois niveaux pour le secteur public. Même le gouvernement de Washington est allé plus loin et a établi un système de classification à cinq niveaux. Il a été salué par les défenseurs des données ouvertes de la région, créant ainsi un espace potentiel pour les fournisseurs du secteur. Diverses sociétés de services financiers, telles que les compagnies d'assurance et les banques, sont les principaux utilisateurs de solutions de classification des données, car elles doivent gérer d'importants volumes d'informations personnelles identifiables (PII) et respecter les réglementations gouvernementales en matière de protection des données.
Analyse du marché par composants
Sur la base des composants, le marché de la classification des données est segmenté en solutions et services. Titus, Boldon James, Digital Guardian, Spirion et Netwrix comptent parmi les principaux acteurs du marché qui répondent aux besoins de protection et de classification des données. Ces entreprises proposent un outil complet de classification des données, accompagné d'une gamme de services garantissant le bon fonctionnement de la solution.
Analyse du marché basée sur les applications
Le marché de la classification des données est segmenté selon les applications : gouvernance, risque et conformité, protection du Web, des mobiles et des e-mails, etc.
Analyse du marché basée sur les secteurs verticaux
Le marché de la classification des données est segmenté selon les secteurs verticaux : BFSI, informatique et télécommunications, médias et divertissement, commerce de détail, éducation, santé, etc. Les banques et autres entreprises du secteur financier utilisent l'apprentissage automatique (ML) pour deux objectifs essentiels : identifier des informations précieuses sur les données et prévenir la fraude. Ces informations permettent d'identifier des opportunités d'investissement ou d'aider les investisseurs à savoir quand négocier.
Les acteurs du marché de la classification des données privilégient des stratégies telles que des initiatives de marché, des acquisitions et des lancements de produits pour maintenir leur position sur ce marché. Voici quelques développements réalisés par les principaux acteurs du marché :
En mars 2020, Netwrix permet aux professionnels de la sécurité et de la gouvernance de l'information de reprendre le contrôle des données confidentielles, réglementées et critiques pour l'entreprise. L'entreprise a lancé Netwrix Data Classification 5.5.2.
En novembre 2018, Titus, leader des solutions de protection des données, a lancé Titus Intelligent Protection. Ce nouvel outil offre un apprentissage automatique basé sur la classification pour réduire les risques de perte de données.
Aperçu régional du marché de la classification des données
Les tendances régionales et les facteurs influençant le marché de la classification des données tout au long de la période de prévision ont été analysés en détail par les analystes de The Insight Partners. Cette section aborde également les segments et la géographie du marché de la classification des données en Amérique du Nord, en Europe, en Asie-Pacifique, au Moyen-Orient et en Afrique, ainsi qu'en Amérique du Sud et en Amérique centrale.
Portée du rapport sur le marché de la classification des données
| Attribut de rapport | Détails |
|---|---|
| Taille du marché en 2019 | US$ 568.80 Million |
| Taille du marché par 2027 | US$ 3,577.49 Million |
| TCAC mondial (2019 - 2027) | 27.6% |
| Données historiques | 2017-2018 |
| Période de prévision | 2020-2027 |
| Segments couverts |
By Solution
|
| Régions et pays couverts |
Amérique du Nord
|
| Leaders du marché et profils d'entreprises clés |
|
Densité des acteurs du marché de la classification des données : comprendre son impact sur la dynamique des entreprises
Le marché de la classification des données connaît une croissance rapide, portée par une demande croissante des utilisateurs finaux, due à des facteurs tels que l'évolution des préférences des consommateurs, les avancées technologiques et une meilleure connaissance des avantages du produit. Face à cette demande croissante, les entreprises élargissent leur offre, innovent pour répondre aux besoins des consommateurs et capitalisent sur les nouvelles tendances, ce qui alimente la croissance du marché.
- Obtenez le Marché de la classification des données Aperçu des principaux acteurs clés

Ankita est une professionnelle dynamique des études de marché et du conseil, forte de plus de 8 ans d'expérience dans les secteurs des technologies, des médias, des TIC, de l'électronique et des semi-conducteurs. Elle a dirigé et réalisé avec succès plus de 100 missions de conseil et d'études pour des clients internationaux tels que Microsoft, Oracle, NEC Corporation, SAP, KPMG et Expeditors International. Ses compétences clés incluent l'analyse de marché, l'analyse de données, la prévision, la formulation de stratégies, la veille concurrentielle et la rédaction de rapports.
Ankita maîtrise parfaitement la gestion de cycles de projet complets, de la conception de propositions avant-vente et des discussions avec les clients jusqu'à la fourniture d'informations exploitables après-vente. Elle maîtrise la gestion d'équipes transverses, la structuration de modules d'études complexes et l'alignement des solutions sur les objectifs commerciaux spécifiques de chaque client. Ses excellentes compétences en communication, leadership et présentation lui ont permis de fournir systématiquement des résultats à forte valeur ajoutée dans des environnements de marché dynamiques et en constante évolution.
- Analyse historique (2 ans), année de base, prévision (7 ans) avec TCAC
- Analyse PEST et SWOT
- Taille du marché Valeur / Volume - Mondial, Régional, Pays
- Industrie et paysage concurrentiel
- Ensemble de données Excel
Témoignages
Le rapport sur le marché des systèmes SCADA d'Insight Partners est complet et fournit des informations précieuses sur les tendances actuelles et les prévisions. L'équipe a fait preuve d'un grand professionnalisme, d'une grande réactivité et d'un grand soutien tout au long du projet. Nous sommes très satisfaits et recommandons vivement leurs services.
RAN KEDEM Partenaire, Reali Technologies LTDJ'ai demandé un rapport sur un marché logiciel très spécifique et l'équipe l'a produit en quelques jours. Les informations étaient très pertinentes et bien présentées. J'ai ensuite demandé des modifications et des ajouts au rapport. L'équipe a de nouveau été très réactive et j'ai reçu le rapport final en moins d'une semaine.
JEAN-HERVÉ JENN Président, Future AnalyticaNous avons collaboré avec The Insight Partners pour une importante étude de marché et des prévisions. Ils nous ont fourni une vision claire des opportunités et des risques, ce qui nous a aidés à élaborer nos plans. Leurs recherches étaient faciles à utiliser et basées sur des données solides. Elles nous ont permis de prendre des décisions éclairées et en toute confiance. Nous les recommandons vivement.
PIYUSH NAGPAL Vice-président principal, Feux de route mondiauxInsight Partners a réalisé une étude de marché pertinente et bien structurée, avec une solide expertise du domaine. Son équipe a fait preuve de professionnalisme et de réactivité tout au long du projet. Son site web convivial a facilité l'accès aux rapports sectoriels. Nous recommandons vivement ses services d'études fiables et de haute qualité.
YUKIHIKO ADACHI PDG, Bleu profond, LLC.C'est la première fois que j'achète une étude de marché auprès de The Insight Partners. J'étais un peu hésitant au début, mais j'ai consulté leur site web et me suis senti plus à l'aise pour prendre le risque d'acheter une étude de marché. Je suis entièrement satisfait de la qualité du rapport et du service client. J'avais plusieurs questions et commentaires concernant le rapport initial, mais après quelques échanges par e-mail avec leur analyste, je pense avoir obtenu un rapport qui pourra alimenter notre processus de planification stratégique. Merci beaucoup pour votre temps et pour avoir rendu cette expérience positive. Je recommanderai sans hésiter vos services et vous serez mon premier contact lorsque nous aurons besoin de données de marché supplémentaires.
JOHN SUZUKI Président-directeur général, administrateur du conseil d'administration, BK TechnologiesJe tiens à vous remercier pour votre soutien et le professionnalisme dont vous avez fait preuve lors du traitement de ma demande d'informations concernant le marché des dispositifs de diagnostic in vitro (DIV) pour les maladies infectieuses au Nigéria. J'apprécie votre patience, vos conseils et votre volonté d'offrir une réduction, ce qui nous a finalement permis de conclure un accord. Je me réjouis de collaborer à nouveau avec The Insight Partners, grâce à l'impression que vous m'avez laissée suite à cette première rencontre.
DR CHIJIOKE DIRECTEUR GÉNÉRAL D'ONYIA, PineCrest Healthcare Ltd.Raison d'acheter
- Prise de décision éclairée
- Compréhension de la dynamique du marché
- Analyse concurrentielle
- Connaissances clients
- Prévisions de marché
- Atténuation des risques
- Planification stratégique
- Justification des investissements
- Identification des marchés émergents
- Amélioration des stratégies marketing
- Amélioration de l'efficacité opérationnelle
- Alignement sur les tendances réglementaires










Débloquez des remises exclusives sur les rapports
Demander maintenant



 Obtenez un échantillon gratuit pour - Marché de la classification des données
Obtenez un échantillon gratuit pour - Marché de la classification des données