Marktwachstum, Größe, Anteil, Trends, Analyse der wichtigsten Akteure und Prognose zur Datenklassifizierung bis 2027
Historische Daten : 2017-2018 | Basisjahr : 2019 | Prognosezeitraum : 2020-2027Marktprognose für Datenklassifizierung bis 2027 – Auswirkungen von COVID-19 und globale Analyse nach Lösung (Lösung, Dienste); Anwendung (GRC, Web-, Mobil- und E-Mail-Schutz, Sonstige); Vertikal (BFSI, IT und Telekommunikation, Medien und Unterhaltung, Einzelhandel, Bildung, Gesundheitswesen, Sonstige)
- Status : Veröffentlicht
- Berichtscode : TIPRE00003043
- Kategorie : Technologie, Medien und Telekommunikation
- Anzahl der Seiten : 151
- Verfügbare Berichtsformate :




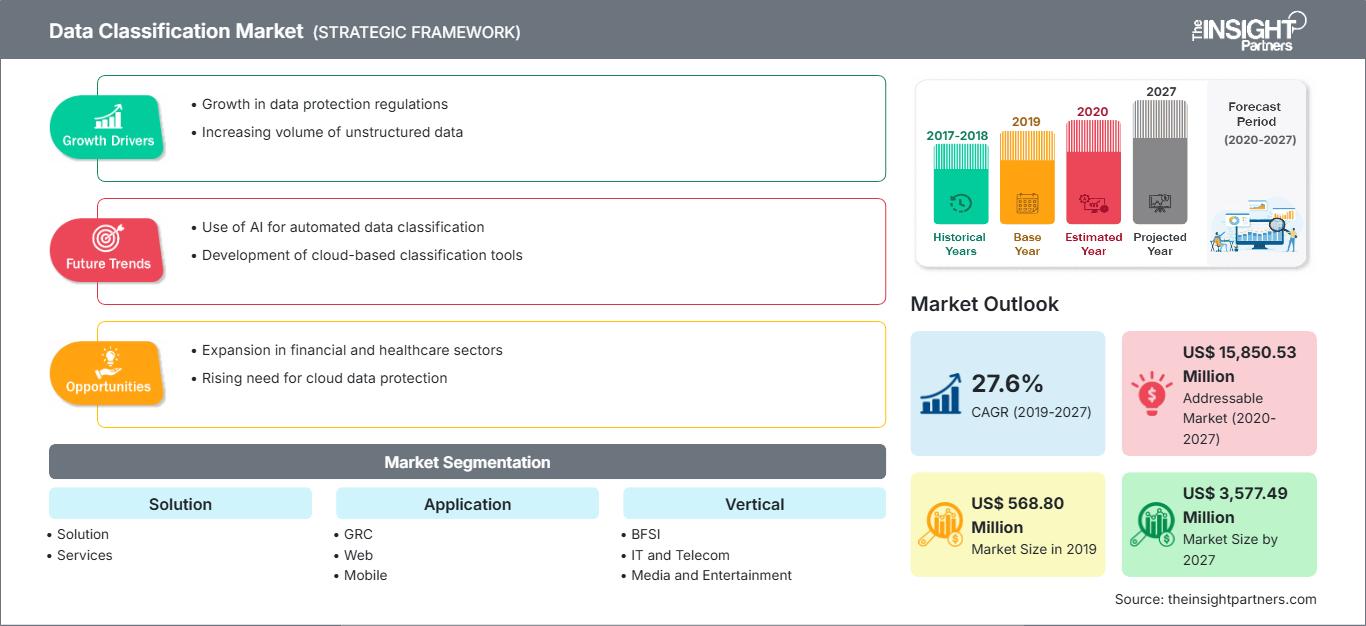
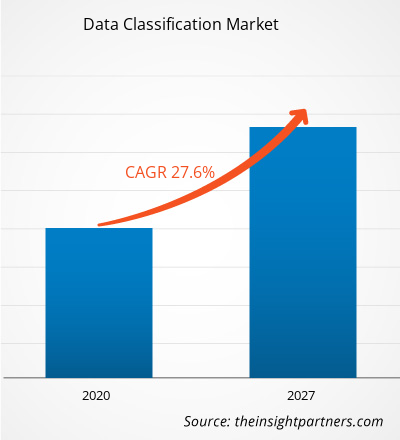
Der Markt für Datenklassifizierung wurde 2019 auf 568,80 Millionen US-Dollar geschätzt und soll bis 2027 3.577,49 Millionen US-Dollar erreichen. Von 2020 bis 2027 wird ein CAGR-Wachstum des Marktes für Datenklassifizierung von 27,6 % erwartet.
Die Datenklassifizierung ist ein Tool, das enorme Datenmengen in verschiedene Registerkarten unterteilt, um das Beste daraus zu machen und gleichzeitig die Vertraulichkeit vertraulicher Daten zu wahren. Die Kommerzialisierung von Datenschutzgesetzen wie der DSGVO und dem Health Insurance Portability and Accountability Act (HIPAA) wirkt sich direkt auf den Umfang der Datenklassifizierung weltweit aus. Zunehmende Geschäftsdaten- und Cloud-Migrationen, die Zunahme der Identifizierung personenbezogener Daten, Bedrohungen der Privatsphäre bei E-Mails, der Einsatz von maschinellem Lernen und die Konvergenz von Datenmanagement und Datenschutz sind einige der Faktoren, die die Datenklassifizierung maßgeblich vorantreiben. Die Datenklassifizierung erfreut sich weltweit großer Beliebtheit. Die Einführung von Datenklassifizierungstools zur Bekämpfung von Cyberbedrohungen ebnet den Weg für das Marktwachstum. Auch die zunehmende Betonung von Datenschutzgesetzen durch Regierungsbehörden in Ländern wie Großbritannien, den USA, Deutschland und Singapur treibt die Akzeptanz der Datenklassifizierung voran. Darüber hinaus beschleunigt die Integration hochentwickelter Technologien wie maschinelles Lernen und künstliche Intelligenz in Datenklassifizierungstools die Leistung und Produktivität des gesamten Unternehmens. Beispielsweise nutzen 40 % der US-Unternehmen ML zur Verbesserung ihrer Vertriebs- und Marketingstrategien, und die europäischen Banken konnten mithilfe von ML ihre Produktverkäufe um 10 % steigern und ihre Abwanderungsraten um 20 % senken.
Der Markt für Datenklassifizierung ist in Komponenten, Anwendungen, Branchen und Regionen segmentiert. Basierend auf den Komponenten hielt das Lösungssegment den größten Anteil am globalen Markt für Datenklassifizierung. Die Datenklassifizierungslösung leitet Sicherheitskontrollen ab, die auf den jeweiligen Datensatz angewendet werden. Basierend auf den Anwendungen dominierte das Segment Web-, Mobil- und E-Mail-Schutz 2019 den globalen Markt für Datenklassifizierung. Mit der zunehmenden Nutzung von E-Mail, Mobil- und Webanwendungen für die Datenübertragung zwischen Unternehmen und Branchen sind Tools für Datenschutz und Datenklassifizierung unverzichtbar geworden. Vertikal betrachtet leistete das BFSI-Segment im Jahr 2019 einen erheblichen Beitrag und wird seine Dominanz im Prognosezeitraum voraussichtlich fortsetzen. Geografisch ist der Markt in fünf Hauptregionen unterteilt: Nordamerika, Europa, Asien-Pazifik (APAC), Naher Osten und Afrika (MEA) sowie Südamerika (SAM).
Passen Sie diesen Bericht Ihren Anforderungen an
Sie erhalten kostenlos Anpassungen an jedem Bericht, einschließlich Teilen dieses Berichts oder einer Analyse auf Länderebene, eines Excel-Datenpakets sowie tolle Angebote und Rabatte für Start-ups und Universitäten.
Markt für Datenklassifizierung: Strategische Einblicke
-
Holen Sie sich die wichtigsten Markttrends aus diesem Bericht.Dieses KOSTENLOSE Beispiel umfasst Datenanalysen, die von Markttrends bis hin zu Schätzungen und Prognosen reichen.
Die USA, Deutschland, Großbritannien und Singapur gehören zu den Ländern, in denen die Regierungen IT-Unternehmen mit Gesetzen zur Datenverschlüsselung und zum Datenschutz reguliert haben, weshalb Technologieunternehmen in diesen Märkten Möglichkeiten finden, ihre Datenklassifizierungsdienste zu bewerben. Die Regierungen der USA und Großbritanniens haben dreistufige Datenklassifizierungssysteme für den öffentlichen Sektor eingerichtet. Sogar die Regierung in Washington ist noch weiter gegangen und hat ein fünfstufiges Klassifizierungssystem eingeführt. Dies wurde von den Open-Data-Befürwortern der Region sehr begrüßt, da es potenziellen Spielraum für Branchenanbieter in diesem Bereich geschaffen hat. Verschiedene Finanzdienstleistungsunternehmen wie Versicherungen und Banken sind die Hauptnutzer von Datenklassifizierungslösungen, da sie mit großen Mengen personenbezogener Daten (PII) und staatlichen Datenschutzbestimmungen zu tun haben.
Komponentenbasierte Markteinblicke
Auf Komponentenbasis ist der Markt für Datenklassifizierung in Lösungen und Dienste segmentiert. Titus, Boldon James, Digital Guardian, Spirion und Netwrix sind einige der führenden Akteure auf dem Markt, die den Bedarf an Datenschutz und Datenklassifizierung decken. Die Unternehmen bieten komplette Datenklassifizierungstools sowie eine Reihe von Services an, um die ordnungsgemäße Leistung der Lösung sicherzustellen.
Anwendungsbasierte Markteinblicke
Basierend auf der Anwendung ist der Markt für Datenklassifizierung in Governance, Risiko und Compliance, Web-, Mobil- und E-Mail-Schutz und Sonstiges unterteilt.
Vertikale Markteinblicke
Basierend auf der Vertikalen ist der Markt für Datenklassifizierung in folgende Bereiche unterteilt: BFSI, IT und Telekommunikation, Medien und Unterhaltung, Einzelhandel, Bildung, Gesundheitswesen und Sonstiges. Banken und verschiedene andere Unternehmen der Finanzbranche nutzen Machine Learning (ML)-Technologie für zwei wesentliche Zwecke: die Gewinnung wertvoller Datenerkenntnisse und die Verhinderung von Betrug. Die Erkenntnisse können Investitionsmöglichkeiten aufzeigen oder Anlegern helfen, den richtigen Zeitpunkt für einen Handel zu finden.
Akteure auf dem Markt für Datenklassifizierung konzentrieren sich auf Strategien wie Marktinitiativen, Akquisitionen und Produkteinführungen, um ihre Position auf dem Markt für Datenklassifizierung zu behaupten. Einige Entwicklungen der wichtigsten Akteure auf dem Markt für Datenklassifizierung sind:
Im März 2020 ermöglicht Netwrix Informationssicherheits- und Governance-Experten, die Kontrolle über vertrauliche, regulierte und geschäftskritische Daten zurückzuerlangen. Das Unternehmen stellte Netwrix Data Classification 5.5.2 vor.
Im November 2018 hat Titus, ein führender Anbieter von Datenschutzlösungen, Titus Intelligent Protection vorgestellt. Das neue Tool bietet klassifizierungsgesteuertes maschinelles Lernen, um das Risiko von Datenverlusten zu senken.
Datenklassifizierung
Regionale Einblicke in den Markt für DatenklassifizierungDie Analysten von The Insight Partners haben die regionalen Trends und Faktoren, die den Markt für Datenklassifizierung im Prognosezeitraum beeinflussen, ausführlich erläutert. In diesem Abschnitt werden auch die Marktsegmente und die geografische Lage in Nordamerika, Europa, dem asiatisch-pazifischen Raum, dem Nahen Osten und Afrika sowie Süd- und Mittelamerika erörtert.
Umfang des Marktberichts zur Datenklassifizierung
| Berichtsattribut | Einzelheiten |
|---|---|
| Marktgröße in 2019 | US$ 568.80 Million |
| Marktgröße nach 2027 | US$ 3,577.49 Million |
| Globale CAGR (2019 - 2027) | 27.6% |
| Historische Daten | 2017-2018 |
| Prognosezeitraum | 2020-2027 |
| Abgedeckte Segmente |
By Lösung
|
| Abgedeckte Regionen und Länder |
Nordamerika
|
| Marktführer und wichtige Unternehmensprofile |
|
Dichte der Marktteilnehmer im Bereich Datenklassifizierung: Verständnis ihrer Auswirkungen auf die Geschäftsdynamik
Der Markt für Datenklassifizierung wächst rasant. Die steigende Nachfrage der Endnutzer ist auf Faktoren wie veränderte Verbraucherpräferenzen, technologische Fortschritte und ein stärkeres Bewusstsein für die Produktvorteile zurückzuführen. Mit der steigenden Nachfrage erweitern Unternehmen ihr Angebot, entwickeln Innovationen, um den Bedürfnissen der Verbraucher gerecht zu werden, und nutzen neue Trends, was das Marktwachstum weiter ankurbelt.
- Holen Sie sich die Markt für Datenklassifizierung Übersicht der wichtigsten Akteure
- Lösung
- Dienste
Markt für Datenklassifizierung – nach Anwendung
- GRC
- Web
- Mobil
- E-Mail-Schutz
- Sonstige
Markt für Datenklassifizierung – nach Branchen
- BFSI
- IT und Telekommunikation
- Medien und Unterhaltung
- Einzelhandel
- Bildung
- Gesundheitswesen
- Sonstige
Markt für Datenklassifizierung – nach Geografie
-
Nordamerika
- USA
- Kanada
- Mexiko
-
Europa
- Frankreich
- Deutschland
- Russland
- Vereinigtes Königreich
- Italien
- Übriges Europa
-
Asien Pazifik (APAC)
- China
- Indien
- Japan
- Australien
- Südkorea
- Rest von APAC
-
MEA
- Saudi-Arabien
- VAE
- Südafrika
- Rest von MEA
-
SAM
- Brasilien
- Argentinien
- Rest von SAM
Datenklassifizierungsmarkt – Unternehmensprofile
- Boldon James
- Google LLC
- Microsoft Corporation
- Open Text Corporation
- DATAGUISE
- Informatica
- Netwrix Corporation
- PKWARE, Inc.
- Titus
- Varonis

Ankita ist eine dynamische Marktforschungs- und Beratungsexpertin mit über 8 Jahren Erfahrung in den Bereichen Technologie, Medien, IKT sowie Elektronik und Halbleiter. Sie hat über 100 Beratungs- und Forschungsaufträge für globale Kunden wie Microsoft, Oracle, NEC Corporation, SAP, KPMG und Expeditors International erfolgreich geleitet und durchgeführt. Zu ihren Kernkompetenzen gehören Marktbewertung, Datenanalyse, Prognose, Strategieformulierung, Wettbewerbsbeobachtung und das Verfassen von Berichten. Ankita ist versiert in der Abwicklung kompletter Projektzyklen – von der Angebotserstellung vor dem Verkauf und Kundengesprächen bis hin zur Bereitstellung umsetzbarer Erkenntnisse nach dem Verkauf. Sie ist versiert in der Leitung funktionsübergreifender Teams, der Strukturierung komplexer Forschungsmodule und der Ausrichtung von Lösungen an kundenspezifischen Geschäftszielen. Ihre ausgezeichneten Kommunikationsfähigkeiten, Führungsqualitäten und Präsentationsfähigkeiten haben es ihr ermöglicht, in einem schnelllebigen und sich entwickelnden Marktumfeld stets wertorientierte Ergebnisse zu liefern.
- Historische Analyse (2 Jahre), Basisjahr, Prognose (7 Jahre) mit CAGR
- PEST- und SWOT-Analyse
- Marktgröße Wert/Volumen – Global, Regional, Land
- Branchen- und Wettbewerbslandschaft
- Excel-Datensatz
Erfahrungsberichte
Der SCADA-Systemmarktbericht von Insight Partners ist umfassend und bietet wertvolle Einblicke in aktuelle Trends und Zukunftsprognosen. Das Team war durchweg hochprofessionell, reaktionsschnell und hilfsbereit. Wir sind sehr zufrieden und können die Dienstleistungen wärmstens empfehlen.
RAN KEDEM Partner, Reali Technologies LTDsIch habe einen Bericht über einen sehr spezifischen Softwaremarkt angefordert, und das Team hat ihn innerhalb weniger Tage erstellt. Die Informationen waren sehr relevant und gut präsentiert. Anschließend habe ich einige Änderungen und Ergänzungen zum Bericht angefordert. Das Team reagierte erneut sehr schnell, und ich erhielt den Abschlussbericht in weniger als einer Woche.
JEAN-HERVE JENN Vorsitzende, Future AnalyticaWir haben mit The Insight Partners für eine wichtige Marktstudie und Prognose zusammengearbeitet. Sie gaben uns klare Einblicke in Chancen und Risiken, die uns bei der Gestaltung unserer Pläne halfen. Ihre Recherchen waren benutzerfreundlich und basierten auf soliden Daten. Sie halfen uns, kluge und sichere Entscheidungen zu treffen. Wir können sie wärmstens empfehlen.
PIYUSH NAGPAL Sr. Vizepräsident, Fernlicht GlobalDie Insight Partners lieferten aufschlussreiche, gut strukturierte Marktforschung mit fundierter Fachkompetenz. Ihr Team war durchweg professionell und reaktionsschnell. Die benutzerfreundliche Website ermöglichte den Zugriff auf Branchenberichte. Wir empfehlen sie wärmstens für zuverlässige und hochwertige Forschungsdienstleistungen.
YUKIHIKO ADACHI Geschäftsführer, Deep Blue, LLC.Dies ist das erste Mal, dass ich einen Marktbericht von The Insight Partners erworben habe. Obwohl ich zunächst unsicher war, besuchte ich die Website und fühlte mich dann sicherer, das Risiko einzugehen und einen Marktbericht zu kaufen. Ich bin mit der Qualität des Berichts und dem Kundenservice rundum zufrieden. Ich hatte einige Fragen und Anmerkungen zum ersten Bericht, aber nach einigen E-Mail-Gesprächen mit dem Analysten bin ich überzeugt, dass ich einen Bericht habe, den ich als Input für unseren strategischen Planungsprozess verwenden kann. Vielen Dank, dass Sie sich die Zeit genommen und dies zu einer positiven Erfahrung gemacht haben. Ich werde Ihren Service auf jeden Fall weiterempfehlen und Sie werden meine erste Anlaufstelle sein, wenn wir weitere Marktdaten benötigen.
JOHN SUZUKI Präsident und Chief Executive Officer, Vorstandsmitglied, BK TechnologiesIch möchte mich für Ihre Unterstützung und die Professionalität bedanken, die Sie bei der Bearbeitung meiner Informationsanfrage zum IVD-Markt für Infektionskrankheiten in Nigeria gezeigt haben. Ich schätze Ihre Geduld, Ihre Beratung und die Tatsache, dass Sie bereit waren, einen Rabatt anzubieten, der uns schließlich den Abschluss eines Geschäfts ermöglichte. Ich freue mich darauf, The Insight Partners in Zukunft wieder zu beauftragen, dank des Eindrucks, den Sie bei dieser ersten Begegnung bei mir hinterlassen haben.
DR. CHIJIOKE ONYIA GESCHÄFTSFÜHRERIN, PineCrest Healthcare Ltd.Grund zum Kauf
- Fundierte Entscheidungsfindung
- Marktdynamik verstehen
- Wettbewerbsanalyse
- Kundeneinblicke
- Marktprognosen
- Risikominimierung
- Strategische Planung
- Investitionsbegründung
- Identifizierung neuer Märkte
- Verbesserung von Marketingstrategien
- Steigerung der Betriebseffizienz
- Anpassung an regulatorische Trends










Exklusive Berichtsrabatte freischalten
Jetzt anfragen



 Kostenlose Probe anfordern für - Markt für Datenklassifizierung
Kostenlose Probe anfordern für - Markt für Datenklassifizierung