
Marktübersicht, Wachstum, Trends, Analyse und Forschungsbericht zur Long-Read-Sequenzierung (2020-2028)
Marktprognose für Long-Read-Sequenzierung bis 2028 – Auswirkungen von COVID-19 und globale Analyse nach Technologie (Einzelmolekül-Echtzeitsequenzierung (SMRT), Nanoporensequenzierung, Loop-Genomik-Long-Read-Sequenzierung), Produkt (Instrumente, Verbrauchsmaterialien, Dienstleistungen), Anwendung (Identifizierung und Feinkartierung struktureller Variationen, Tandem-Repeat-Sequenzierung, Pseudogen-Diskriminierung, Auflösung der Allelphasenbildung, Reproduktionsgenomik, Krebs, virale und mikrobielle Sequenzierung, Sonstiges), Arbeitsablauf (Vorsequenzierung, Sequenzierung, Datenanalyse), Endbenutzer (akademische Forschungsinstitute, Krankenhäuser und Kliniken, Pharma- und Biotechnologieunternehmen) und Geografie
- Status : Veröffentlicht
- Berichtscode : TIPRE00006815
- Kategorie : Biowissenschaften
- Anzahl der Seiten : 125
- Verfügbare Berichtsformate :


- Datum der letzten Aktualisierung : June 17, 2024

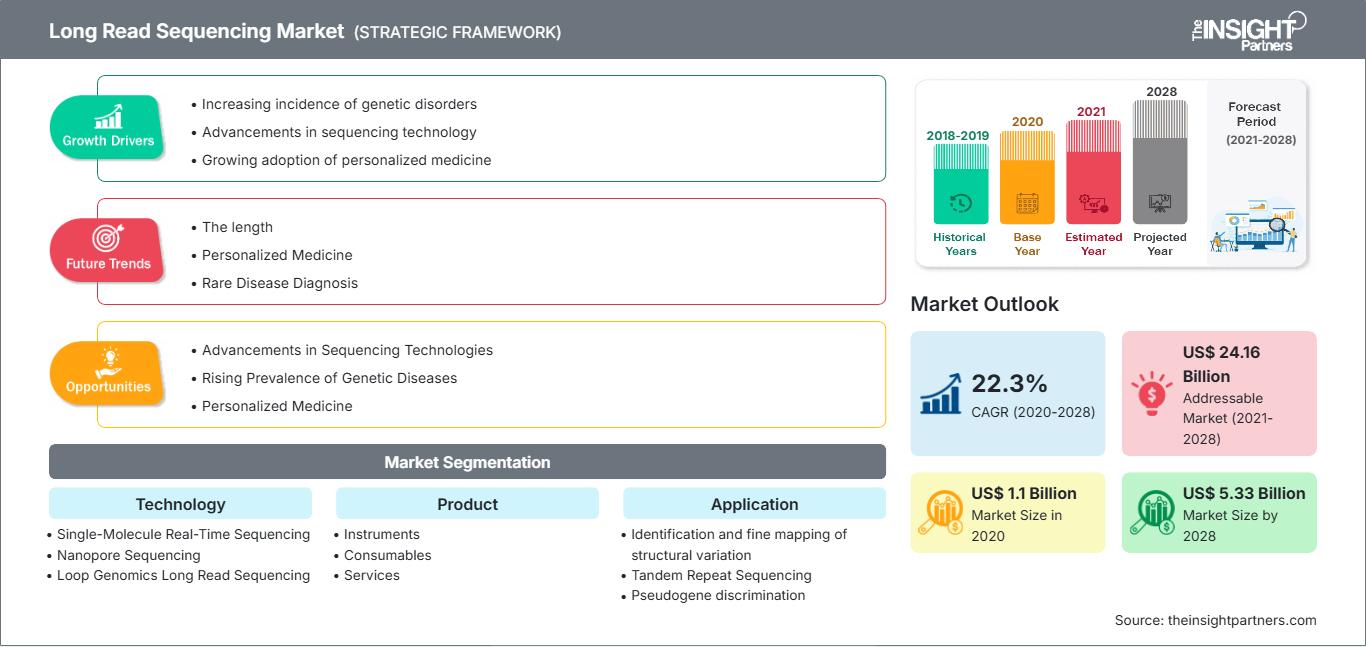
Der Markt für Long-Read-Sequenzierung hatte im Jahr 2020 einen Wert von 1.101,15 Millionen US-Dollar und soll bis 2028 voraussichtlich 5.334,68 Millionen US-Dollar erreichen; für den Zeitraum 2021–2028 wird ein CAGR-Wachstum von 22,3 % erwartet.
Die Long-Read-Sequenzierung ist eine DNA-Sequenzierungstechnik. Sie bietet zahlreiche deutliche Vorteile gegenüber Sequenzierungstechnologien der nächsten Generation, wie z. B. die präzisere Sequenzierung von DNA, die dieselben DNA-Abschnitte enthält, die sich im Genom wiederholen. Viele Erwachsene ab 60 Jahren leiden an zwei oder mehr chronischen Krankheiten. Laut Zwillingsforschung spielen Gene eine Rolle bei chronischen Krankheiten wie Herz-Kreislauf-Erkrankungen, Diabetes, Fettleibigkeit, rheumatoider Arthritis, Alzheimer (AD) und Depressionen. Laut den Centers for Disease Control and Prevention (CDC) leiden in den USA etwa sechs von zehn Personen an mindestens einer chronischen Krankheit, und vier von zehn an zwei oder mehr. Krebs wird hauptsächlich durch genomische Fehler verursacht. Forscher haben Krebsgenome mithilfe verschiedener, sich schnell entwickelnder Sequenzierungstechnologien analysiert, um den molekularen Status von Krebszellen besser zu verstehen und ihre Schwachstellen wie Treibermutationen oder Genexpression aufzudecken. Mithilfe von Long-Read-Technologien konnten die Forscher neue Formen krebsartiger Mutationen erkennen und klassifizieren, darunter auch komplexe Strukturvarianten in der Haplotypauflösung. In den letzten Jahren wurden mehrere Long-Read-Sequenzierungstechnologien entwickelt und eingesetzt. Beispielsweise entwickelte Pacific Biosciences die SMRT-Sequenzierung, eine der Long-Read-Methoden (PacBio). Long-Read-Sequenzierung wird immer häufiger eingesetzt, und Krebsstudien, die auf Long-Read-Daten basieren, nehmen zu und entwickeln sich weiter, um komplexe Krebsgenome zu entschlüsseln.
Passen Sie diesen Bericht Ihren Anforderungen an
Sie erhalten kostenlos Anpassungen an jedem Bericht, einschließlich Teilen dieses Berichts oder einer Analyse auf Länderebene, eines Excel-Datenpakets sowie tolle Angebote und Rabatte für Start-ups und Universitäten.
Markt für Long-Read-Sequenzierung: Strategische Einblicke
-
Holen Sie sich die wichtigsten Markttrends aus diesem Bericht.Dieses KOSTENLOSE Beispiel umfasst Datenanalysen, die von Markttrends bis hin zu Schätzungen und Prognosen reichen.
Markteinblicke: Vorteile der Long-Read-Sequenzierung treiben den Markt für Long-Read-Sequenzierung voran
Long-Read-Technologien überwinden frühe Einschränkungen hinsichtlich Genauigkeit und Durchsatz und finden zunehmend Anwendung in der Genomik. Long-Read-Sequenzierung oder Sequenzierung der dritten Generation bietet mehrere Vorteile gegenüber Short-Read-Sequenzierung. Während Short-Read-Sequenzer wie die Instrumente HiSeq, NovaSeq, NextSeq und MiSeq von Illumina, die Modelle MGISEQ und BGISEQ von BGI oder die Ion Torrent-Sequenzer von Thermo Fisher Reads von bis zu 600 Basen produzieren, generieren Long-Read-Sequenzierungstechnologien regelmäßig Reads von über 10 kb. Darüber hinaus können Long Reads die De-novo-Assemblierung, die Mapping-Sicherheit, die Identifizierung von Transkript-Isoformen und die Erkennung struktureller Varianten verbessern. Darüber hinaus eliminiert die Long-Read-Sequenzierung nativer Moleküle, d. h. DNA und RNA, den Amplifikationsbias, während Basenmodifikationen erhalten bleiben. Mit den kontinuierlichen Fortschritten bei Genauigkeit, Durchsatz und Kostensenkung haben diese Möglichkeiten die Long-Read-Sequenzierung zu einer Option für ein breites Anwendungsspektrum in der Genomik für Modell- und Nicht-Modellorganismen gemacht.
Technologie: Einblicke
Der globale Markt für Long-Read-Sequenzierung ist technologiebasiert in Einzelmolekül-Echtzeitsequenzierung (SMRT), Nanoporensequenzierung und Loop-Genomik-Long-Read-Sequenzierung segmentiert. Das Segment Einzelmolekül-Echtzeitsequenzierung (SMRT) hatte 2020 den größten Marktanteil. Allerdings wird für das Segment Loop-Genomik-Long-Read-Sequenzierung im Prognosezeitraum die höchste CAGR des Marktes erwartet.Langlesesequenzierung
Regionale Einblicke in den Markt für LanglesesequenzierungDie Analysten von The Insight Partners haben die regionalen Trends und Faktoren, die den Markt für Long-Read-Sequenzierung im Prognosezeitraum beeinflussen, ausführlich erläutert. In diesem Abschnitt werden auch die Marktsegmente und die geografische Lage in Nordamerika, Europa, dem asiatisch-pazifischen Raum, dem Nahen Osten und Afrika sowie Süd- und Mittelamerika erörtert.
Umfang des Marktberichts zur Sequenzierung langer Lesevorgänge
| Berichtsattribut | Einzelheiten |
|---|---|
| Marktgröße in 2020 | US$ 1.1 Billion |
| Marktgröße nach 2028 | US$ 5.33 Billion |
| Globale CAGR (2020 - 2028) | 22.3% |
| Historische Daten | 2018-2019 |
| Prognosezeitraum | 2021-2028 |
| Abgedeckte Segmente |
By Technologie
|
| Abgedeckte Regionen und Länder |
Nordamerika
|
| Marktführer und wichtige Unternehmensprofile |
|
Langfassung: Sequenzierung der Marktteilnehmerdichte: Verständnis ihrer Auswirkungen auf die Geschäftsdynamik
Der Markt für Long Read Sequencing wächst rasant. Die steigende Nachfrage der Endnutzer ist auf Faktoren wie veränderte Verbraucherpräferenzen, technologische Fortschritte und ein stärkeres Bewusstsein für die Produktvorteile zurückzuführen. Mit der steigenden Nachfrage erweitern Unternehmen ihr Angebot, entwickeln Innovationen, um den Bedürfnissen der Verbraucher gerecht zu werden, und nutzen neue Trends, was das Marktwachstum weiter ankurbelt.
- Holen Sie sich die Markt für Long-Read-Sequenzierung Übersicht der wichtigsten Akteure
Nach Technologie
- Einzelmolekül-Echtzeitsequenzierung (SMRT)
- Nanoporensequenzierung
- Loop-Genomik-Long-Read-Sequenzierung
Nach Produkt
- Instrumente
- Verbrauchsmaterialien
- Dienstleistungen
Nach Anwendung
- Identifizierung und Feinkartierung struktureller Variationen
- Tandem-Repeat-Sequenzierung
- Pseudogene Diskriminierung
- Auflösung der Allel-Phase
- Reproduktion Genomik
- Krebs
- Virale und mikrobielle Sequenzierung
- Sonstige
Nach Arbeitsablauf
- Vorsequenzierung
- Sequenzierung
- Datenanalyse
Nach Endbenutzer
- Akademische Forschungsinstitute
- Krankenhäuser und Kliniken
- Pharma- und Biotechnologieunternehmen
Nach Geografie
-
Nordamerika
- USA
- Kanada
- Mexiko
-
Europa
- Frankreich
- Deutschland
- Italien
- Großbritannien
- Spanien
-
Asien Pazifik
- China
- Indien
- Südkorea
- Japan
- Australien
-
Naher Osten und Afrika
- Südafrika
- Saudi-Arabien
- VAE
-
Süd- und Mittelamerika
- Brasilien
- Argentinien
Firmenprofile
- Oxford Nanopore Technologies
- Tataa Biocenter
- Illumina, Inc
- Perkinelmer Inc.
- F. Hoffmann-La Roche Ltd.
- Baseclear BV
- Bionano Genomics
- Longas Technologies
- Pacific Biosciences of California, Inc.
- Quantapore, Inc.

Mrinal ist eine erfahrene Research-Analystin mit über 8 Jahren Erfahrung in der Marktanalyse und Beratung im Bereich Life Sciences. Mit ihrer strategischen Denkweise und ihrem unerschütterlichen Streben nach Exzellenz hat sie sich umfassende Expertise in den Bereichen Pharmaprognosen, Marktchancenbewertung und Entwicklung von Branchen-Benchmarks angeeignet. Ihre Arbeit konzentriert sich darauf, umsetzbare Erkenntnisse zu liefern, die Kunden fundierte strategische Entscheidungen ermöglichen. Mrinals Kernkompetenz liegt in der Übersetzung komplexer quantitativer Datensätze in aussagekräftige Geschäftsinformationen. Ihr analytischer Scharfsinn ist entscheidend für die Entwicklung von Go-to-Market-Strategien (GTM) und die Erschließung von Wachstumschancen in der Pharma- und Medizinproduktebranche. Als vertrauenswürdige Beraterin konzentriert sie sich konsequent auf die Optimierung von Arbeitsabläufen und die Etablierung von Best Practices, um so Innovation und Betriebseffizienz für ihre Kunden zu fördern.
- Umfassende Analyse der Marktgröße und Prognosen
- Detaillierte Segmentierungsanalyse
- Tiefgehende Bewertung der Marktdynamik
- Einblicke auf regionaler und nationaler Ebene
- Wettbewerbslandschaft und Unternehmens-Benchmarking
- Strategische Business Intelligence
Erfahrungsberichte
Der SCADA-Systemmarktbericht von Insight Partners ist umfassend und bietet wertvolle Einblicke in aktuelle Trends und Zukunftsprognosen. Das Team war durchweg hochprofessionell, reaktionsschnell und hilfsbereit. Wir sind sehr zufrieden und können die Dienstleistungen wärmstens empfehlen.
RAN KEDEM Partner, Reali Technologies LTDsIch habe einen Bericht über einen sehr spezifischen Softwaremarkt angefordert, und das Team hat ihn innerhalb weniger Tage erstellt. Die Informationen waren sehr relevant und gut präsentiert. Anschließend habe ich einige Änderungen und Ergänzungen zum Bericht angefordert. Das Team reagierte erneut sehr schnell, und ich erhielt den Abschlussbericht in weniger als einer Woche.
JEAN-HERVE JENN Vorsitzende, Future AnalyticaWir haben mit The Insight Partners für eine wichtige Marktstudie und Prognose zusammengearbeitet. Sie gaben uns klare Einblicke in Chancen und Risiken, die uns bei der Gestaltung unserer Pläne halfen. Ihre Recherchen waren benutzerfreundlich und basierten auf soliden Daten. Sie halfen uns, kluge und sichere Entscheidungen zu treffen. Wir können sie wärmstens empfehlen.
PIYUSH NAGPAL Sr. Vizepräsident, Fernlicht GlobalDie Insight Partners lieferten aufschlussreiche, gut strukturierte Marktforschung mit fundierter Fachkompetenz. Ihr Team war durchweg professionell und reaktionsschnell. Die benutzerfreundliche Website ermöglichte den Zugriff auf Branchenberichte. Wir empfehlen sie wärmstens für zuverlässige und hochwertige Forschungsdienstleistungen.
YUKIHIKO ADACHI Geschäftsführer, Deep Blue, LLC.Dies ist das erste Mal, dass ich einen Marktbericht von The Insight Partners erworben habe. Obwohl ich zunächst unsicher war, besuchte ich die Website und fühlte mich dann sicherer, das Risiko einzugehen und einen Marktbericht zu kaufen. Ich bin mit der Qualität des Berichts und dem Kundenservice rundum zufrieden. Ich hatte einige Fragen und Anmerkungen zum ersten Bericht, aber nach einigen E-Mail-Gesprächen mit dem Analysten bin ich überzeugt, dass ich einen Bericht habe, den ich als Input für unseren strategischen Planungsprozess verwenden kann. Vielen Dank, dass Sie sich die Zeit genommen und dies zu einer positiven Erfahrung gemacht haben. Ich werde Ihren Service auf jeden Fall weiterempfehlen und Sie werden meine erste Anlaufstelle sein, wenn wir weitere Marktdaten benötigen.
JOHN SUZUKI Präsident und Chief Executive Officer, Vorstandsmitglied, BK TechnologiesIch möchte mich für Ihre Unterstützung und die Professionalität bedanken, die Sie bei der Bearbeitung meiner Informationsanfrage zum IVD-Markt für Infektionskrankheiten in Nigeria gezeigt haben. Ich schätze Ihre Geduld, Ihre Beratung und die Tatsache, dass Sie bereit waren, einen Rabatt anzubieten, der uns schließlich den Abschluss eines Geschäfts ermöglichte. Ich freue mich darauf, The Insight Partners in Zukunft wieder zu beauftragen, dank des Eindrucks, den Sie bei dieser ersten Begegnung bei mir hinterlassen haben.
DR. CHIJIOKE ONYIA GESCHÄFTSFÜHRERIN, PineCrest Healthcare Ltd.Grund zum Kauf
- Fundierte Entscheidungsfindung
- Marktdynamik verstehen
- Wettbewerbsanalyse
- Kundeneinblicke
- Marktprognosen
- Risikominimierung
- Strategische Planung
- Investitionsbegründung
- Identifizierung neuer Märkte
- Verbesserung von Marketingstrategien
- Steigerung der Betriebseffizienz
- Anpassung an regulatorische Trends













