
Marché de l’analyse de texte – Analyse des tendances et de la croissance | Année de prévision 2031
Taille et prévisions du marché de l'analyse de texte (2021-2031), parts mondiales et régionales, tendances et opportunités de croissance. Rapport d'analyse : par type de déploiement (cloud et sur site), technologie (NLP, AML et hybride), application (analyse prédictive, veille concurrentielle, détection de fraude/spam et surveillance des réseaux sociaux), secteur vertical (BFSI, télécommunications, biens de grande consommation, administration publique, enseignement et formation, droit et propriété intellectuelle, santé, produits pharmaceutiques, chimie et matériaux, commerce de détail et autres), et géographie (Amérique du Nord, Europe, Asie-Pacifique, Amérique du Sud et centrale).
- Statut : Données publiées
- Code du rapport : TIPTE100000198
- Catégorie : Technologie, médias et télécommunications
- Nombre de pages : 260
- Formats de rapport disponibles :


- Date de dernière mise à jour : August 08, 2025

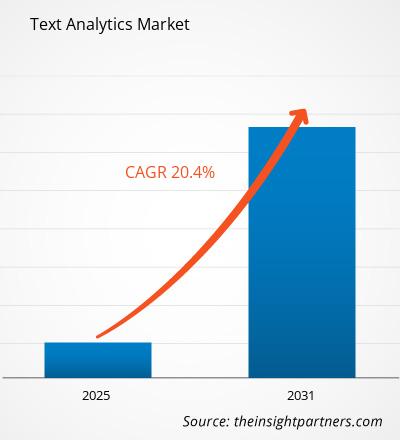
Le marché de l'analyse de texte devrait atteindre 29,53 milliards de dollars américains d'ici 2031. Il devrait enregistrer un TCAC de 18,1 % entre 2025 et 2031.
Ce rapport est segmenté par type de déploiement (cloud et sur site) et analyse le marché en fonction de la technologie (traitement automatique du langage naturel [TALN], lutte contre le blanchiment d'argent [LCB] et solutions hybrides). Il examine également le marché par application (analyse prédictive, veille concurrentielle, détection des fraudes et du spam, surveillance des médias sociaux) et par secteur d'activité (services financiers, télécommunications, biens de consommation courante, secteur public, enseignement supérieur, droit et propriété intellectuelle, santé, industrie pharmaceutique, chimie et matériaux, commerce de détail). Une analyse détaillée est fournie aux niveaux mondial, régional et national pour chacun de ces segments clés.
Le rapport inclut la taille du marché et les prévisions pour tous les segments, exprimées en dollars américains. Ce rapport fournit également des statistiques clés sur la situation actuelle des principaux acteurs du marché, ainsi que des informations sur les tendances actuelles et les opportunités émergentes.
Objectif du rapport
Le rapport « Marché de l'analyse de texte » de The Insight Partners vise à décrire le paysage actuel et la croissance future, les principaux facteurs de croissance, les défis et les opportunités. Il fournira des informations précieuses à divers acteurs du secteur, tels que :
- Fournisseurs de technologies/Fabricants : Pour comprendre l'évolution de la dynamique du marché et identifier les opportunités de croissance potentielles, afin de prendre des décisions stratégiques éclairées.
- Investisseurs : Pour réaliser une analyse approfondie des tendances concernant le taux de croissance du marché, les projections financières et les opportunités tout au long de la chaîne de valeur.
- Organismes de réglementation : Pour encadrer les politiques et les activités du marché afin de minimiser les abus, de préserver la confiance des investisseurs et de garantir l'intégrité et la stabilité du marché.
Segmentation du marché de l'analyse de texte : Type de déploiement
- Cloud et sur site
Technologie
- NLP
- AML
- Hybride
Application
- Analyse prédictive
- Veille concurrentielle
- Détection de fraude/spam
- Surveillance des médias sociaux
Secteur vertical
- BFSI
- Télécommunications
- Biens de consommation courante
- Secteur public
- Enseignement supérieur
- Juridique et propriété intellectuelle
- Santé
- Industrie pharmaceutique
- Chimie et matériaux
- Commerce de détail
Vous bénéficierez d’une personnalisation sur n’importe quel rapport - gratuitement - y compris des parties de ce rapport, ou une analyse au niveau du pays, un pack de données Excel, ainsi que de profiter d’offres exceptionnelles et de réductions pour les start-ups et les universités
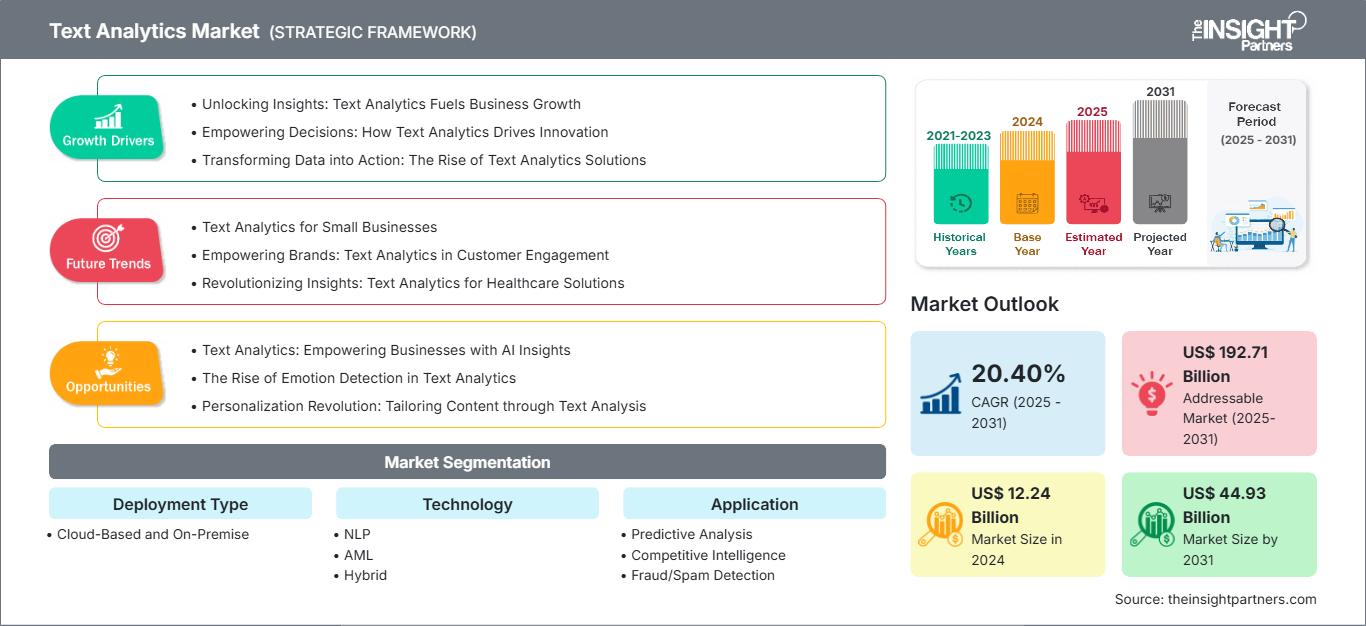
Marché de l'analyse de texte: Perspectives stratégiques
-
Obtenez les principales tendances clés du marché de ce rapport.Cet échantillon GRATUIT comprendra une analyse de données, allant des tendances du marché aux estimations et prévisions.
Facteurs de croissance du marché de l'analyse de texte
- Exploiter les données : l'analyse de texte stimule la croissance des entreprises
- Prendre des décisions éclairées : comment l'analyse de texte favorise l'innovation
- Transformer les données en actions : l'essor des solutions d'analyse de texte
Tendances futures du marché de l'analyse de texte
- L'analyse de texte pour les PME
- Renforcer les marques : l'analyse de texte au service de l'engagement client
- Révolutionner les données : l'analyse de texte pour les solutions de santé
Opportunités du marché de l'analyse de texte
- Analyse de texte : donner aux entreprises les moyens d'exploiter les données de l'IA
- L'essor de la détection des émotions dans l'analyse de texte
- Révolution de la personnalisation : adapter le contenu grâce à l'analyse de texte
Marché de l'analyse de texte
Les analystes de The Insight Partners ont analysé en détail les tendances régionales et les facteurs influençant le marché de l'analyse de texte tout au long de la période prévisionnelle. Cette section aborde également les segments et la répartition géographique du marché de la gestion des troubles du rythme cardiaque en Amérique du Nord, en Europe, en Asie-Pacifique, au Moyen-Orient et en Afrique, ainsi qu'en Amérique du Sud et centrale.
Portée du rapport sur le marché de l'analyse de texte
| Attribut de rapport | Détails |
|---|---|
| Taille du marché en 2024 | US$ 9.22 Billion |
| Taille du marché par 2031 | US$ 29.53 Billion |
| TCAC mondial (2025 - 2031) | 18.1% |
| Données historiques | 2021-2023 |
| Période de prévision | 2025-2031 |
| Segments couverts |
By Type de déploiement
|
| Régions et pays couverts |
Amérique du Nord
|
| Leaders du marché et profils d'entreprises clés |
|
Densité des acteurs du marché de l'analyse de texte : comprendre son impact sur la dynamique des entreprises
Le marché de l'analyse de texte connaît une croissance rapide, portée par une demande croissante des utilisateurs finaux, elle-même alimentée par l'évolution des préférences des consommateurs, les progrès technologiques et une meilleure connaissance des avantages du produit. Face à cette demande grandissante, les entreprises élargissent leur offre, innovent pour répondre aux besoins des consommateurs et tirent parti des tendances émergentes, ce qui stimule davantage la croissance du marché.
- Obtenez le Marché de l'analyse de texte Aperçu des principaux acteurs clés
Points clés de la vente
- Couverture exhaustive : Ce rapport analyse en détail les produits, services, types et utilisateurs finaux du marché de l’analyse de texte, offrant ainsi une vision globale.
- Analyse d’experts : Ce rapport repose sur une connaissance approfondie du secteur et des analystes.
- Informations actualisées : Grâce à sa couverture des informations et tendances les plus récentes, ce rapport garantit la pertinence des données pour les entreprises.
- Options de personnalisation : Ce rapport peut être personnalisé pour répondre aux besoins spécifiques des clients et s’adapter parfaitement à leurs stratégies commerciales.
Ce rapport d’étude de marché sur l’analyse de texte peut donc contribuer à décrypter et comprendre le contexte sectoriel et les perspectives de croissance. Malgré quelques points à améliorer, les avantages de ce rapport l’emportent généralement sur les inconvénients.

Ankita est une professionnelle dynamique des études de marché et du conseil, forte de plus de 8 ans d'expérience dans les secteurs des technologies, des médias, des TIC, de l'électronique et des semi-conducteurs. Elle a dirigé et réalisé avec succès plus de 100 missions de conseil et d'études pour des clients internationaux tels que Microsoft, Oracle, NEC Corporation, SAP, KPMG et Expeditors International. Ses compétences clés incluent l'analyse de marché, l'analyse de données, la prévision, la formulation de stratégies, la veille concurrentielle et la rédaction de rapports.
Ankita maîtrise parfaitement la gestion de cycles de projet complets, de la conception de propositions avant-vente et des discussions avec les clients jusqu'à la fourniture d'informations exploitables après-vente. Elle maîtrise la gestion d'équipes transverses, la structuration de modules d'études complexes et l'alignement des solutions sur les objectifs commerciaux spécifiques de chaque client. Ses excellentes compétences en communication, leadership et présentation lui ont permis de fournir systématiquement des résultats à forte valeur ajoutée dans des environnements de marché dynamiques et en constante évolution.
- Analyse complète de la taille du marché et prévisions
- Analyse détaillée de la segmentation
- Évaluation approfondie de la dynamique du marché
- Aperçus par région et par pays
- Paysage concurrentiel et analyse comparative des entreprises
- Intelligence économique stratégique
Témoignages
Le rapport sur le marché des systèmes SCADA d'Insight Partners est complet et fournit des informations précieuses sur les tendances actuelles et les prévisions. L'équipe a fait preuve d'un grand professionnalisme, d'une grande réactivité et d'un grand soutien tout au long du projet. Nous sommes très satisfaits et recommandons vivement leurs services.
RAN KEDEM Partenaire, Reali Technologies LTDJ'ai demandé un rapport sur un marché logiciel très spécifique et l'équipe l'a produit en quelques jours. Les informations étaient très pertinentes et bien présentées. J'ai ensuite demandé des modifications et des ajouts au rapport. L'équipe a de nouveau été très réactive et j'ai reçu le rapport final en moins d'une semaine.
JEAN-HERVÉ JENN Président, Future AnalyticaNous avons collaboré avec The Insight Partners pour une importante étude de marché et des prévisions. Ils nous ont fourni une vision claire des opportunités et des risques, ce qui nous a aidés à élaborer nos plans. Leurs recherches étaient faciles à utiliser et basées sur des données solides. Elles nous ont permis de prendre des décisions éclairées et en toute confiance. Nous les recommandons vivement.
PIYUSH NAGPAL Vice-président principal, Feux de route mondiauxInsight Partners a réalisé une étude de marché pertinente et bien structurée, avec une solide expertise du domaine. Son équipe a fait preuve de professionnalisme et de réactivité tout au long du projet. Son site web convivial a facilité l'accès aux rapports sectoriels. Nous recommandons vivement ses services d'études fiables et de haute qualité.
YUKIHIKO ADACHI PDG, Bleu profond, LLC.C'est la première fois que j'achète une étude de marché auprès de The Insight Partners. J'étais un peu hésitant au début, mais j'ai consulté leur site web et me suis senti plus à l'aise pour prendre le risque d'acheter une étude de marché. Je suis entièrement satisfait de la qualité du rapport et du service client. J'avais plusieurs questions et commentaires concernant le rapport initial, mais après quelques échanges par e-mail avec leur analyste, je pense avoir obtenu un rapport qui pourra alimenter notre processus de planification stratégique. Merci beaucoup pour votre temps et pour avoir rendu cette expérience positive. Je recommanderai sans hésiter vos services et vous serez mon premier contact lorsque nous aurons besoin de données de marché supplémentaires.
JOHN SUZUKI Président-directeur général, administrateur du conseil d'administration, BK TechnologiesJe tiens à vous remercier pour votre soutien et le professionnalisme dont vous avez fait preuve lors du traitement de ma demande d'informations concernant le marché des dispositifs de diagnostic in vitro (DIV) pour les maladies infectieuses au Nigéria. J'apprécie votre patience, vos conseils et votre volonté d'offrir une réduction, ce qui nous a finalement permis de conclure un accord. Je me réjouis de collaborer à nouveau avec The Insight Partners, grâce à l'impression que vous m'avez laissée suite à cette première rencontre.
DR CHIJIOKE DIRECTEUR GÉNÉRAL D'ONYIA, PineCrest Healthcare Ltd.Raison d'acheter
- Prise de décision éclairée
- Compréhension de la dynamique du marché
- Analyse concurrentielle
- Connaissances clients
- Prévisions de marché
- Atténuation des risques
- Planification stratégique
- Justification des investissements
- Identification des marchés émergents
- Amélioration des stratégies marketing
- Amélioration de l'efficacité opérationnelle
- Alignement sur les tendances réglementaires













