
Textanalysemarkt – Erkenntnisse aus globaler und regionaler Analyse – Prognose bis 2031
Marktgröße und Prognosen für Textanalyse (2021 – 2031), globaler und regionaler Anteil, Trends und Berichtsabdeckung zur Analyse von Wachstumschancen: nach Bereitstellungstyp (Cloud-basiert und vor Ort), Technologie (NLP, AML und Hybrid), Anwendung (Prädiktive Analyse, Wettbewerbsanalyse, Betrugs-/Spam-Erkennung und Social-Media-Überwachung) und Vertikal (BFSI, Telekommunikation, FMCG, Regierung, Wissenschaft und Bildung, Recht und geistiges Eigentum, Gesundheitswesen, Pharmazeutika, Chemie und Materialien, Einzelhandel und andere) und Geografie (Nordamerika, Europa, Asien-Pazifik sowie Süd- und Mittelamerika)
- Status : Veröffentlichte Daten
- Berichtscode : TIPTE100000198
- Kategorie : Technologie, Medien und Telekommunikation
- Anzahl der Seiten : 260
- Verfügbare Berichtsformate :


- Datum der letzten Aktualisierung : August 08, 2025

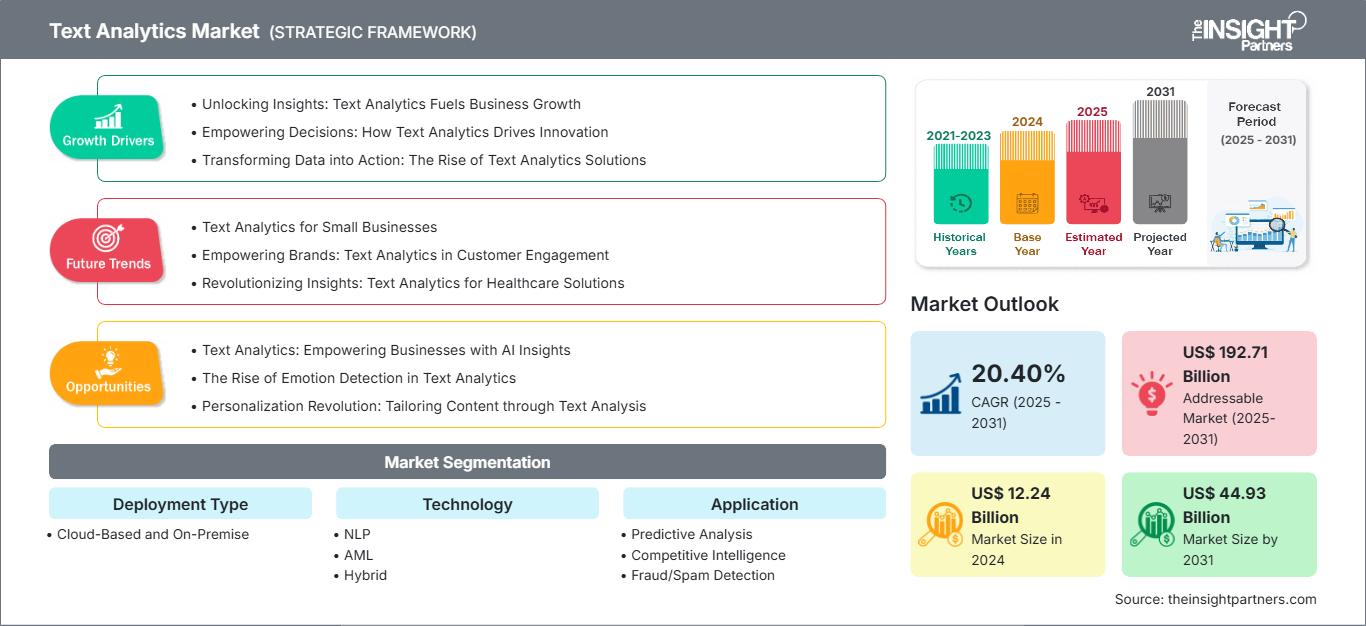
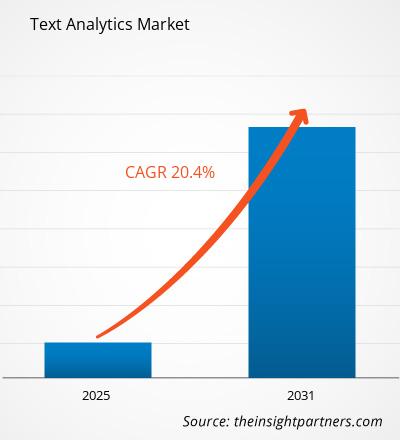
Der Markt für Textanalyse wird bis 2031 voraussichtlich ein Volumen von 29,53 Milliarden US-Dollar erreichen. Für den Zeitraum 2025–2031 wird ein jährliches Wachstum von 18,1 % erwartet.
Der Bericht ist nach Bereitstellungsart (Cloud-basiert und On-Premise) kategorisiert und analysiert den Markt zudem nach Technologie (NLP, AML, Hybrid). Er untersucht den Markt außerdem nach Anwendung (Predictive Analytics, Competitive Intelligence, Betrugs-/Spam-Erkennung, Social-Media-Monitoring) und Branchen (Banken, Finanzdienstleistungen und Versicherungen, Telekommunikation, Konsumgüter, Regierung, Hochschulwesen/Bildung, Recht und geistiges Eigentum, Gesundheitswesen, Pharma, Chemie und Werkstoffe, Einzelhandel). Für jedes dieser Schlüsselsegmente wird eine detaillierte Aufschlüsselung auf globaler, regionaler und Länderebene bereitgestellt. Der Bericht enthält Marktgrößen und Prognosen für alle Segmente, angegeben in US-Dollar. Der Bericht liefert zudem wichtige Statistiken zum aktuellen Marktstatus führender Akteure sowie Einblicke in vorherrschende Markttrends und neue Chancen.
Zweck des Berichts
Der Bericht „Text Analytics Market“ von The Insight Partners beschreibt die aktuelle Marktlage und das zukünftige Wachstum, die wichtigsten Treiber, Herausforderungen und Chancen. Er bietet Einblicke für verschiedene Akteure im Markt, darunter:
- Technologieanbieter/Hersteller: Um die sich entwickelnde Marktdynamik zu verstehen und potenzielle Wachstumschancen zu erkennen, können sie fundierte strategische Entscheidungen treffen.
- Investoren: Um eine umfassende Trendanalyse hinsichtlich Marktwachstumsrate, Finanzprognosen und Chancen entlang der Wertschöpfungskette durchzuführen.
- Regulierungsbehörden: Um Richtlinien zu regulieren und Aktivitäten auf dem Markt zu überwachen, mit dem Ziel, Missbrauch zu minimieren, das Vertrauen der Investoren zu wahren und die Integrität und Stabilität des Marktes zu gewährleisten.
Marktsegmentierung für Textanalysen | Bereitstellungsart
- Cloud-basiert und On-Premise
Technologie
- NLP
- AML
- Hybrid
Anwendung
- Predictive Analytics
- Competitive Intelligence
- Betrugs-/Spam-Erkennung
- Social-Media-Monitoring
Branchen
- BFSI
- Telekommunikation
- FMCG
- Regierung
- Akademie/Bildung
- Recht & Geistiges Eigentum
- Gesundheitswesen
- Pharmazeutika
- Chemie & Werkstoffe
- Einzelhandel
Sie erhalten kostenlos Anpassungen an jedem Bericht, einschließlich Teilen dieses Berichts oder einer Analyse auf Länderebene, eines Excel-Datenpakets sowie tolle Angebote und Rabatte für Start-ups und Universitäten.
Markt für Textanalysen: Strategische Einblicke
-
Holen Sie sich die wichtigsten Markttrends aus diesem Bericht.Dieses KOSTENLOSE Beispiel umfasst Datenanalysen, die von Markttrends bis hin zu Schätzungen und Prognosen reichen.
Wachstumstreiber des Marktes für Textanalyse
- Erkenntnisse freisetzen: Textanalyse fördert das Geschäftswachstum
- Fundierte Entscheidungen treffen: Wie Textanalyse Innovationen vorantreibt
- Daten in Maßnahmen umsetzen: Der Aufstieg von Textanalyselösungen
Zukunftstrends des Marktes für Textanalyse
- Textanalyse für kleine Unternehmen
- Marken stärken: Textanalyse in der Kundenbindung
- Revolutionäre Erkenntnisse: Textanalyse für Lösungen im Gesundheitswesen
Marktchancen für Textanalyse
- Textanalyse: KI-gestützte Erkenntnisse für Unternehmen
- Der Aufstieg der Emotionserkennung in der Textanalyse
- Revolution der Personalisierung: Inhalte durch Textanalyse individuell anpassen
Markt für Textanalyse
Die regionalen Trends und Einflussfaktoren auf den Markt für Textanalyse im gesamten Prognosezeitraum wurden von den Analysten von The Insight Partners ausführlich erläutert. Dieser Abschnitt behandelt außerdem die Marktsegmente und die geografische Verteilung des Marktes für das Management von Herzrhythmusstörungen in Nordamerika, Europa, dem asiatisch-pazifischen Raum, dem Nahen Osten und Afrika sowie Süd- und Mittelamerika.
Umfang des Marktberichts zu Textanalyse
| Berichtsattribut | Einzelheiten |
|---|---|
| Marktgröße in 2024 | US$ 9.22 Billion |
| Marktgröße nach 2031 | US$ 29.53 Billion |
| Globale CAGR (2025 - 2031) | 18.1% |
| Historische Daten | 2021-2023 |
| Prognosezeitraum | 2025-2031 |
| Abgedeckte Segmente |
By Bereitstellungstyp
|
| Abgedeckte Regionen und Länder |
Nordamerika
|
| Marktführer und wichtige Unternehmensprofile |
|
Dichte der Akteure im Markt für Textanalyse: Auswirkungen auf die Geschäftsdynamik
Der Markt für Textanalyse wächst rasant, angetrieben durch die steigende Nachfrage der Endnutzer. Gründe hierfür sind unter anderem sich wandelnde Verbraucherpräferenzen, technologische Fortschritte und ein wachsendes Bewusstsein für die Vorteile des Produkts. Mit steigender Nachfrage erweitern Unternehmen ihr Angebot, entwickeln innovative Lösungen, um den Bedürfnissen der Verbraucher gerecht zu werden, und nutzen neue Trends, was das Marktwachstum zusätzlich beflügelt.
- Holen Sie sich die Markt für Textanalysen Übersicht der wichtigsten Akteure
Wichtigste Verkaufsargumente
- Umfassende Abdeckung: Der Bericht bietet eine umfassende Analyse der Produkte, Dienstleistungen, Typen und Endnutzer des Marktes für Textanalyse und vermittelt so ein ganzheitliches Bild.
- Expertenanalyse: Der Bericht basiert auf dem fundierten Wissen von Branchenexperten und Analysten.
- Aktuelle Informationen: Der Bericht gewährleistet Geschäftsrelevanz durch die Berücksichtigung aktueller Informationen und Datentrends.
- Anpassungsmöglichkeiten: Dieser Bericht kann an spezifische Kundenanforderungen angepasst werden und sich optimal in die Geschäftsstrategien integrieren.
Der Forschungsbericht zum Markt für Textanalyse kann somit maßgeblich dazu beitragen, das Branchenszenario und die Wachstumsaussichten zu entschlüsseln und zu verstehen. Auch wenn einige berechtigte Bedenken bestehen, überwiegen die Vorteile dieses Berichts insgesamt die Nachteile.

Ankita ist eine dynamische Marktforschungs- und Beratungsexpertin mit über 8 Jahren Erfahrung in den Bereichen Technologie, Medien, IKT sowie Elektronik und Halbleiter. Sie hat über 100 Beratungs- und Forschungsaufträge für globale Kunden wie Microsoft, Oracle, NEC Corporation, SAP, KPMG und Expeditors International erfolgreich geleitet und durchgeführt. Zu ihren Kernkompetenzen gehören Marktbewertung, Datenanalyse, Prognose, Strategieformulierung, Wettbewerbsbeobachtung und das Verfassen von Berichten. Ankita ist versiert in der Abwicklung kompletter Projektzyklen – von der Angebotserstellung vor dem Verkauf und Kundengesprächen bis hin zur Bereitstellung umsetzbarer Erkenntnisse nach dem Verkauf. Sie ist versiert in der Leitung funktionsübergreifender Teams, der Strukturierung komplexer Forschungsmodule und der Ausrichtung von Lösungen an kundenspezifischen Geschäftszielen. Ihre ausgezeichneten Kommunikationsfähigkeiten, Führungsqualitäten und Präsentationsfähigkeiten haben es ihr ermöglicht, in einem schnelllebigen und sich entwickelnden Marktumfeld stets wertorientierte Ergebnisse zu liefern.
- Umfassende Analyse der Marktgröße und Prognosen
- Detaillierte Segmentierungsanalyse
- Tiefgehende Bewertung der Marktdynamik
- Einblicke auf regionaler und nationaler Ebene
- Wettbewerbslandschaft und Unternehmens-Benchmarking
- Strategische Business Intelligence
Erfahrungsberichte
Der SCADA-Systemmarktbericht von Insight Partners ist umfassend und bietet wertvolle Einblicke in aktuelle Trends und Zukunftsprognosen. Das Team war durchweg hochprofessionell, reaktionsschnell und hilfsbereit. Wir sind sehr zufrieden und können die Dienstleistungen wärmstens empfehlen.
RAN KEDEM Partner, Reali Technologies LTDsIch habe einen Bericht über einen sehr spezifischen Softwaremarkt angefordert, und das Team hat ihn innerhalb weniger Tage erstellt. Die Informationen waren sehr relevant und gut präsentiert. Anschließend habe ich einige Änderungen und Ergänzungen zum Bericht angefordert. Das Team reagierte erneut sehr schnell, und ich erhielt den Abschlussbericht in weniger als einer Woche.
JEAN-HERVE JENN Vorsitzende, Future AnalyticaWir haben mit The Insight Partners für eine wichtige Marktstudie und Prognose zusammengearbeitet. Sie gaben uns klare Einblicke in Chancen und Risiken, die uns bei der Gestaltung unserer Pläne halfen. Ihre Recherchen waren benutzerfreundlich und basierten auf soliden Daten. Sie halfen uns, kluge und sichere Entscheidungen zu treffen. Wir können sie wärmstens empfehlen.
PIYUSH NAGPAL Sr. Vizepräsident, Fernlicht GlobalDie Insight Partners lieferten aufschlussreiche, gut strukturierte Marktforschung mit fundierter Fachkompetenz. Ihr Team war durchweg professionell und reaktionsschnell. Die benutzerfreundliche Website ermöglichte den Zugriff auf Branchenberichte. Wir empfehlen sie wärmstens für zuverlässige und hochwertige Forschungsdienstleistungen.
YUKIHIKO ADACHI Geschäftsführer, Deep Blue, LLC.Dies ist das erste Mal, dass ich einen Marktbericht von The Insight Partners erworben habe. Obwohl ich zunächst unsicher war, besuchte ich die Website und fühlte mich dann sicherer, das Risiko einzugehen und einen Marktbericht zu kaufen. Ich bin mit der Qualität des Berichts und dem Kundenservice rundum zufrieden. Ich hatte einige Fragen und Anmerkungen zum ersten Bericht, aber nach einigen E-Mail-Gesprächen mit dem Analysten bin ich überzeugt, dass ich einen Bericht habe, den ich als Input für unseren strategischen Planungsprozess verwenden kann. Vielen Dank, dass Sie sich die Zeit genommen und dies zu einer positiven Erfahrung gemacht haben. Ich werde Ihren Service auf jeden Fall weiterempfehlen und Sie werden meine erste Anlaufstelle sein, wenn wir weitere Marktdaten benötigen.
JOHN SUZUKI Präsident und Chief Executive Officer, Vorstandsmitglied, BK TechnologiesIch möchte mich für Ihre Unterstützung und die Professionalität bedanken, die Sie bei der Bearbeitung meiner Informationsanfrage zum IVD-Markt für Infektionskrankheiten in Nigeria gezeigt haben. Ich schätze Ihre Geduld, Ihre Beratung und die Tatsache, dass Sie bereit waren, einen Rabatt anzubieten, der uns schließlich den Abschluss eines Geschäfts ermöglichte. Ich freue mich darauf, The Insight Partners in Zukunft wieder zu beauftragen, dank des Eindrucks, den Sie bei dieser ersten Begegnung bei mir hinterlassen haben.
DR. CHIJIOKE ONYIA GESCHÄFTSFÜHRERIN, PineCrest Healthcare Ltd.Grund zum Kauf
- Fundierte Entscheidungsfindung
- Marktdynamik verstehen
- Wettbewerbsanalyse
- Kundeneinblicke
- Marktprognosen
- Risikominimierung
- Strategische Planung
- Investitionsbegründung
- Identifizierung neuer Märkte
- Verbesserung von Marketingstrategien
- Steigerung der Betriebseffizienz
- Anpassung an regulatorische Trends













